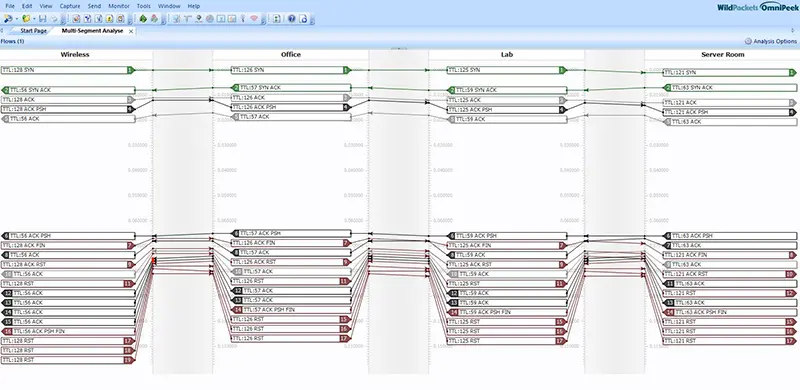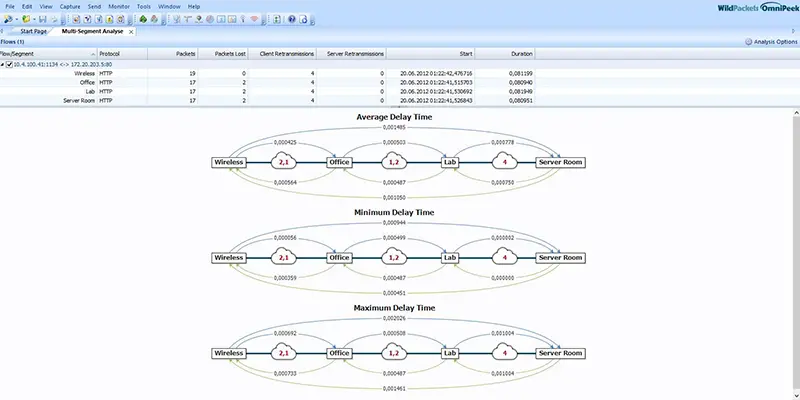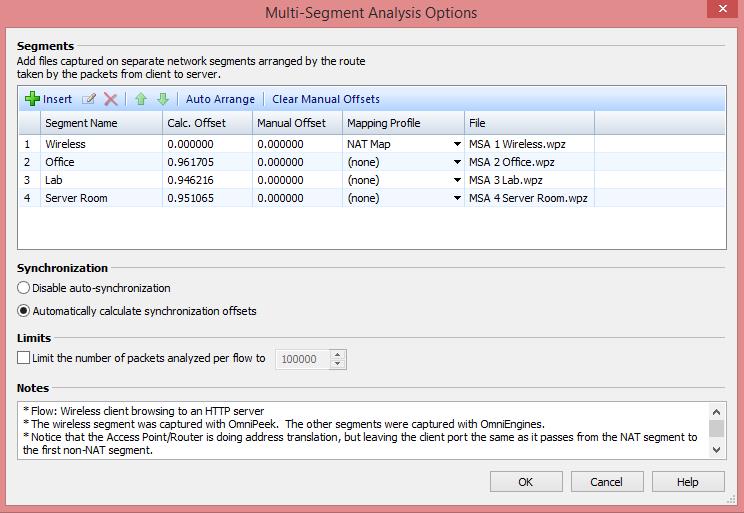
Als Latenz (auch Latenzzeit) wird die Zeit bezeichnet, die benötigt wird, um ein Datenpaket über ein Netzwerk zu senden.
Latenz kann auf unterschiedliche Weise gemessen werden: bidirektional (beide Richtungen), monodirektional (eine Richtung), usw.
Die Latenzzeit kann von jedem Teilstück der Kommunikationsverbindung, über welche das Datenpaket gesendet wird, beeinflusst werden: den Arbeitsplatz, die WAN-Verbindungen, Router, lokale Netzwerke (LAN), Server … und letztendlich kann diese – für große Netzwerke – durch die Lichtgeschwindigkeit begrenzt sein.
Die Durchsatzrate ist definiert als gesendete/empfangene Datenmenge innerhalb einer definierten Zeiteinheit. Die UDP-Durchsatzrate wird von der Latenz nicht beeinflusst.
UDP ist ein Protokoll, das verwendet wird, um Daten über ein IP-Netzwerk zu senden. Eines der Prinzipien von UDP ist, dass angenommen wird, dass die gesendeten Pakete vom Empfänger auch empfangen werden (oder eine entsprechende Steuerung findet auf einer anderen Schicht, beispielsweise einer Anwendung, statt).
Theoretisch bzw. für bestimmte Protokolle (bei welchen auf keiner anderen Schicht eine Steuerung stattfindet – beispielsweise bei monodirektionalen Übertragungen) wird die Rate, zu der Datenpakete durch den Sender gesendet werden können, nicht von der Zeit, die zur Auslieferung an den Empfänger benötigt wird (=Latenz), beeinflusst., Der Sender wird unabhängig von dieser eine definierte Anzahl an Datenpaketen pro Sekunde senden, die wiederum von anderen Faktoren abhängt (Anwendung, Betriebssystem, Ressourcen, …).
Warum wird TCP direkt von der Latenz beeinflusst:
- TCP dagegen ist ein komplexeres Protokoll, da es einen Mechanismen integriert, der prüft, ob sämtliche Datenpakete auch korrekt geliefert werden. Dieser Mechanismus wird Bestätigung (engl. acknowledgement) genannt: Er veranlasst den Empfänger, an den Sender ein spezifisches Paket oder Flag (ACK-Paket bzw. ACK-Flag) zu senden, das den korrekten Empfang des Datenpakets bestätigt. Der Effizienz wegen werden nicht alle Datenpakete einzeln bestätigt: Der Sender wartet entsprechend nicht auf eine Bestätigung nach jedem einzelnen Paket, um die nächsten Datenpakete zu senden. Tatsächlich wird die Anzahl der Datenpakete, die gesendet werden können, bevor ein korrespondierendes Bestätigungspaket erhalten werden muss, von einem Wert, der als TCP Sendefenster (engl. TCP Congestion Window) bezeichnet wird, gesteuert.
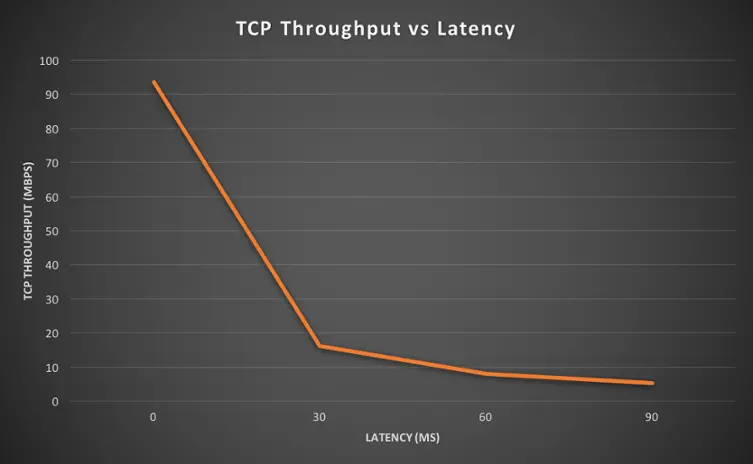
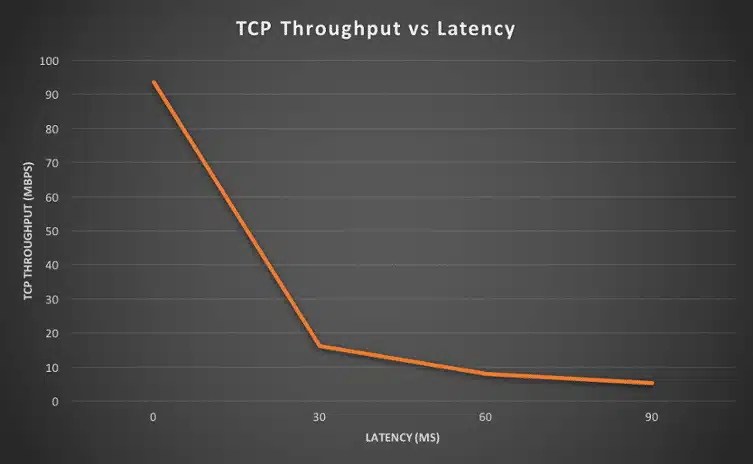
| Round trip latency | TCP Throughput |
| 0ms | 93.5 Mbps |
| 30ms | 16.2 Mbps |
| 60ms | 8.07 Mbps |
| 90ms | 5.32 Mbps |
Nehmen wir hypothetisch an, dass kein Paket verloren geht:
- Der Sender wird ein erstes Kontingent an Datenpaketen gleichzeitig senden (entsprechend dem TCP Congestion Window). Erhält der Sender das Bestätigungspaket, wird das TCP Congestion Window vergrößert. Sukzessiv wird also die Anzahl an Paketen, die in einem bestimmten Zeitraum gleichzeitig gesendet werden können, steigen (Durchsatzrate). Die Verzögerung, mit welcher die Bestätigungspakete empfangen werden (=Latenz), hat einen Einfluss darauf, wie schnell das TCP Congestion Window vergrößert wird (entsprechend auch auf die Durchsatzrate).
Ist die Latenz hoch, bedeutet dies, dass der Sender länger untätig ist (keine neuen Pakete sendet), was wiederum die Geschwindigkeit, mit welcher die Durchsatzrate steigt, reduziert.
Die Testwerte (Quelle: http://smutz.us/techtips/NetworkLatency.html) sind sehr deutlich: Warum wird TCP durch wiederholte Paketsendungen (Retransmissions) und Datenverlust beeinflusst?
Der TCP Congestion Window Mechanismus geht folgendermaßen mit fehlenden Bestätigungspaketen um:
- Bleibt das Bestätigungspaket nach einer fest definierten Zeit (Timer) aus, wird das Paket als verloren eingestuft und das TCP Congestion Window, also die Anzahl der gleichzeitig gesendeten Pakete, wird halbiert (die Durchsatzrate entsprechend auch – dies korrespondiert mit der Wahrnehmung einer restringierten Kapazität irgendwo auf dem Verbindungsweg seitens des Senders); die Größe des TCP Windows kann wieder ansteigen, wenn die Bestätigungspakete korrekt empfangen werden.
Datenverlust hat zwei Effekte auf die Geschwindigkeit der Datenübertragung:
- Die Pakete müssen erneut gesendet werden (selbst wenn lediglich das Bestätigungspaket verloren gegangen ist, die Datenpakete aber empfangen wurden) und das TCP Congestion Window wird keine optimale Durchsatzrate zulassen: Dies gilt unabhängig vom Grund für den Verlust der Bestätigungspakete (Überlastung, Serverprobleme, Art der Paketschnürung, …) Ich hoffe, dies hilft Ihnen dabei, die Auswirkungen von Retransmissions/Datenverlusten auf die Effektivität Ihrer TCP-Anwendungen zu verstehen.
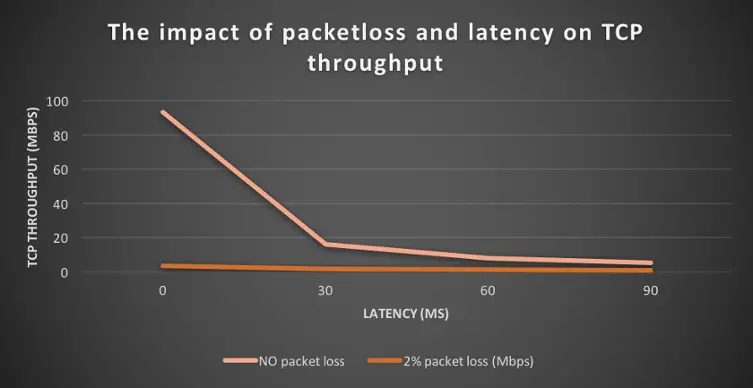
With 2% packetloss, the TCP throughput is between 6 and 25 lower than with no packet loss.
| Round trip latency | TCP Throughput with no packet loss | TCP Throughput with 2% packet loss |
| 0 ms | 93.5 Mbps | 3.72 Mbps |
| 30 ms | 16.2 Mbps | 1.63 Mbps |
| 60 ms | 8.7 Mbps | 1.33 Mbps |
| 90 ms | 5.32 Mbps | 0.85 Mbps |