Was kann bei einem TCP-Handshake schief gehen?
Hier ist der erster Artikel einer Serie, die alle Informationen enthält, die Sie zur Behebung von Leistungsproblemen von Anwendungen benötigen, welche auf dem TCP-Protokoll basieren.
Schauen wir uns an, wie TCP-Sessions aufgebaut werden … und was schief gehen kann!
Das TCP-Protokoll ist ein verbindungsorientiertes Protokoll, was bedeutet, dass eine Verbindung aufgebaut und aufrechterhalten wird, bis die Anwendungsprogramme an jedem Ende den Austausch von Nachrichten abgeschlossen haben. TCP arbeitet mit dem Internet Protocol (IP).
TCP bietet eine zuverlässige, geordnete und fehlerfreie Übertragung. Um dies zu tun, besitzt TCP einige Funktionen, wie zum Beispiel Handshake, Reset, Fin, Ack, Push-Pakete und andere Arten von Flags, um die Verbindung aufrechtzuerhalten und keine Informationen zu verlieren.
TCP wird mit vielen funktionellen Protokollen verwendet, wie beispielsweise HTTP. Daher ist es wichtig zu wissen, wie TCP-Probleme diagnostiziert werden können. In dieser Artikelserie werden wir diese TCP-Metainformationen erläutern und erklären, warum sie für eine Fehlerbehebung wichtig sind und wie sie mit PerformanceVision (PV) ganz leicht gemessen werden können.
Wie wird eine Session gestartet? TCP-Handshake und Verbindungszeit
Eine TCP-Verbindung, die auch als 3-Wege-Handshake bezeichnet wird, erfolgt über SYN, SYN + ACK und ACK-Pakete. Aus diesem Handshake können wir eine Leistungsmetrik mit dem Namen Connection Time (CT) ermitteln, die zusammenfasst, wie schnelle eine Session zwischen einem Client und einem Server über ein Netzwerk aufgebaut werden kann. Weitere Informationen finden Sie in diesem hervorragendem Artikel auf Wikipedia.
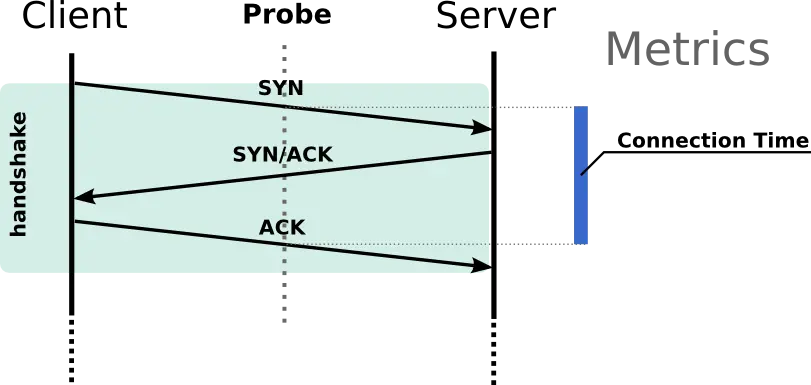
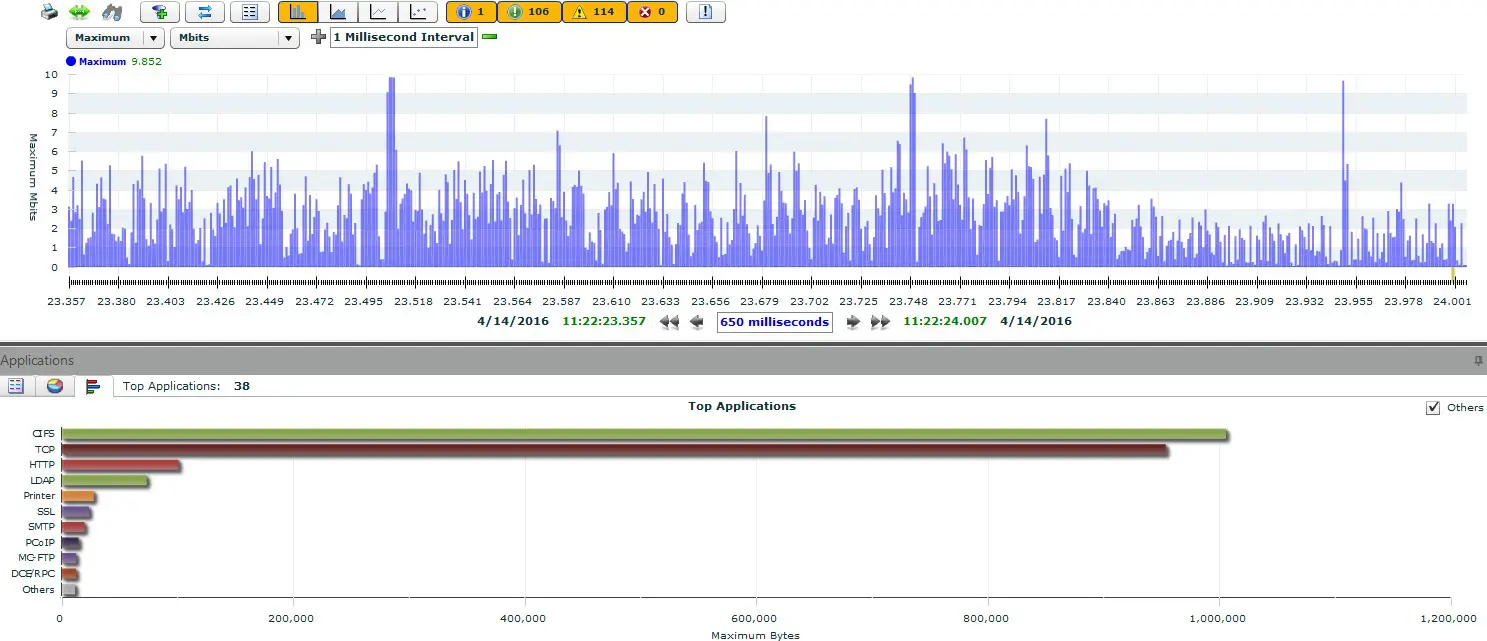
Abb.1 – Wie TCP Handshakes analysiert werden
Die drei Schritte eines TCP-Handshakes sind:
1. Das ‚SYN‘ ist das erste Paket, das von einem Client an einen Server gesendet wird, es verlangt buchstäblich von einem Server, eine Verbindung mit ihm aufzubauen.
2. Wenn es möglich ist, antwortet der Server mit einem "SYN + ACK", was bedeutet, "Ich haben Ihre ‚SYN‘ erhalten und ich bin damit EINVERSTANDEN"
3. Schließlich sendet der Client ein ‚ACK‘, um die Verbindung zu bestätigen.
Wie TCP-Verbindungsfehler diagnostiziert werden
1 – SYN ohne Verbindungen
Die erste Sache, die Sie mit PV leicht diagnostizieren können, lautet: "Können meine Clients eine Verbindung zu meinen Servern herstellen?" Gehen Sie im PV-Menü zu Applikation – → Clients, wählen die Registerkarte TCP und setzen den Filter mit dem Namen “Nur einseitigen Fluss". Dadurch sehen wir nur den Verkehr vom Client zum Server und keine Antwort vom Server.
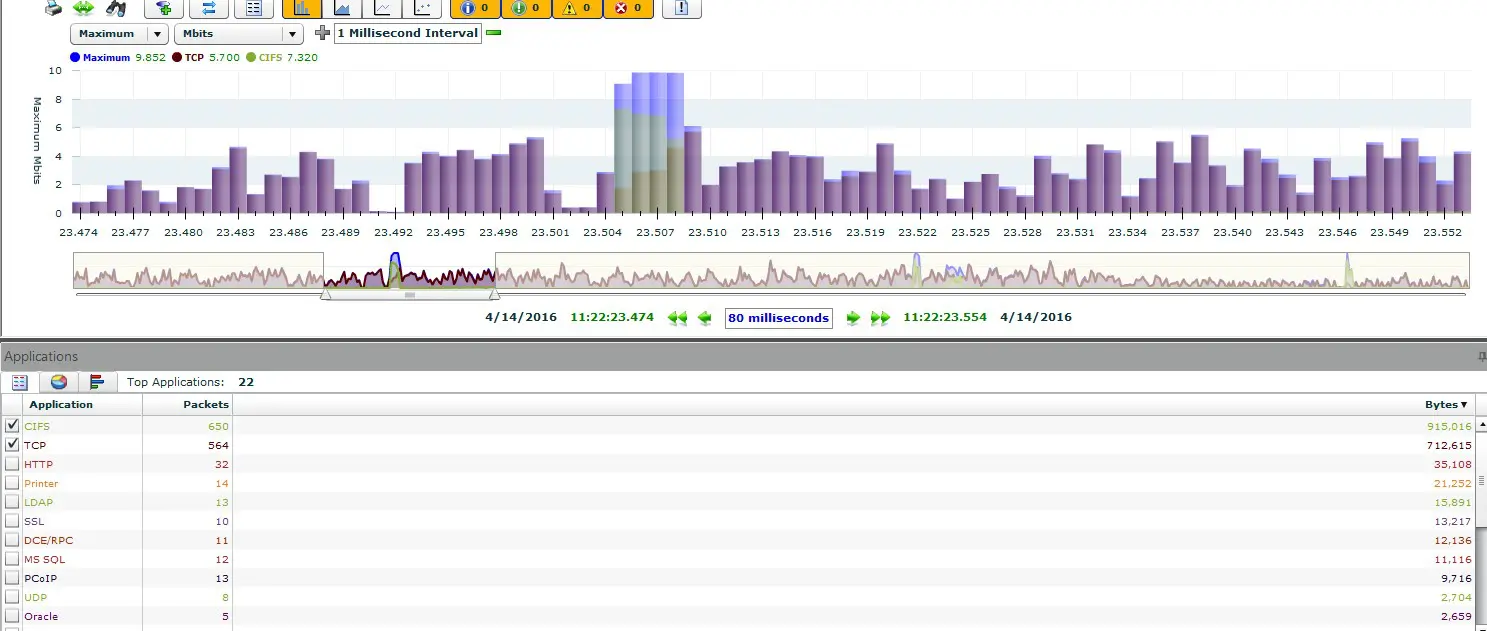
Abb.2 – Nur auf einseitige Flows filtern
Dies bedeutet, dass Sie nur die Top-Client-IPs mit nur einem Fluss vom Client und ohne Antwort sehen möchten.
|
Für fortgeschrittene Benutzer von PerformanceVision Wir haben den Filter so festgelegt, dass nur einseitige Flows zu sehen sind, wodurch größtenteils ‚SYN‘ Probleme angezeigt werden, aber Sie könnten auch andere Arten von Flows erhalten. Um lediglich die ‚SYN‘ ohne Verbindungen zu ermitteln, werden Sie einenbenutzerdefinierten Filter verwenden müssen: syn.count > 0 and ct.count = 0 |
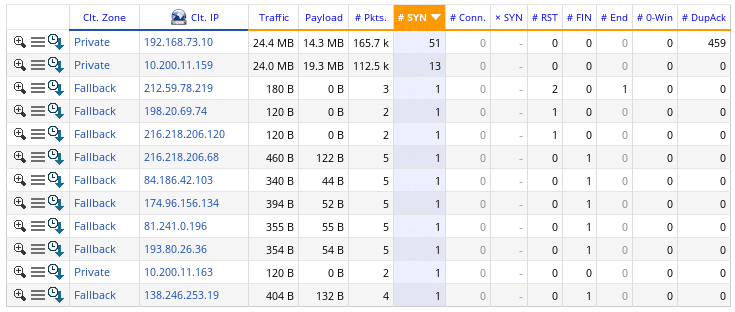
Abb.3 – PV hat einseitige Flows gefunden und diese sortiert
Wie Sie auf den obigen Ergebnissen sehen können, gibt es mehrere IPs, die eine Verbindung zu einem Server (SYN> 0) fordern, aber keine Verbindung zu ihnen herstellen können (Connections = 0).
Hier sind häufige Fehlerfälle:
- Eine Firewall verweigert diese Verbindungen – Sie können dieselbe Anfrage auf Client Zones (im selben Menü) anwenden, um festzustellen, ob sich die IPs in derselben Zone befinden.
- Der Server existiert nicht mehr oder ist nicht verfügbar – dies geschieht häufig, wenn eine Server-IP geändert wird, aber einige Clients auch weiterhin die alte IP anfragen.
2 – Schlechte Verbindungsraten
In einer perfekten Welt sollten Sie 1 ‚SYN‘ pro TCP-Verbindung erhalten. PV stellt eine Metrik zur Verfügung, um diese Verbindungseffizienz zu sehen, was durch eine ‚SYN‘ pro Verbindungsrate (dies entspricht der Anzahl der SYN-Pakete, die mit der Anzahl der TCP-Sitzungen verglichen werden, die eingerichtet wurden) dargestellt wird. Diese Metrik befindet sich in den "Details" Tabellen und kann über die Registerkarte "TCP" geöffnet werden. Sie können auch die zeitliche Entwicklung über Anwendung → benutzerdefinierte Diagramme grafisch darstellen.
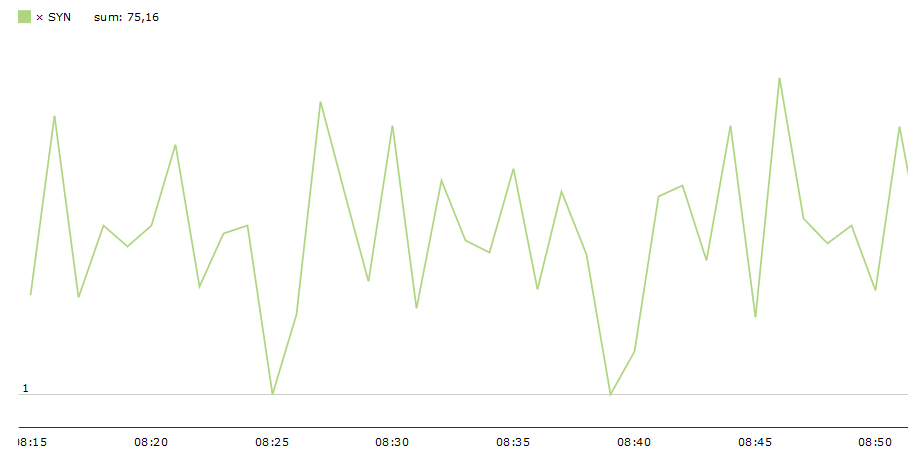
Abb.4 – PV benutzerdefinierte SYN/Conn Tabellen
Eine schlechte „SYN“-Effizienz kann manchmal auch durch ein Netzwerkproblem ausgelöst werden. Somit wird die Fehlverbindung durch einen Paketverlust oder Kontingenz verursacht. Sie können diese Vermutung überprüfen, indem Sie die Verbindungszeit betrachten. Wenn diese niedrig bleibt und sich auf mehrere Hosts auswirkt, dann ist es wahrscheinlich ein Netzwerkproblem.
Wenn hingegen die Verbindungszeit hoch ist, aber das Problem beim Server liegt, ist dieser überlastet und kann nicht auf alle Clientanfragen antworten. Wenn schließlich die ‚SYN‘-Rate sehr groß ist, dann könnten Sie Sicherheitsprobleme haben, wie zum Beispiel einen DDOS-Angriff.
|
Fortgeschrittene Funktionen von PerformanceVision Die Netzwerklatenz – RTT (Round Trip Time) – dies kann Ihnen einen weiteren Hinweis dafür geben, dass das Problem auf der Netzwerkseite liegt. PV stellt das RTT in der Metrik der Netzwerkleistung zur Verfügung. |
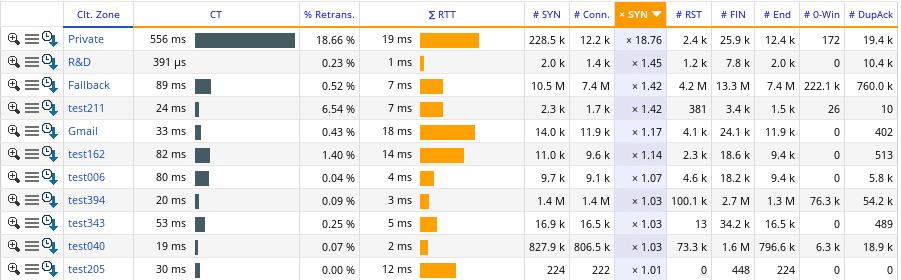
Abb.5 – Eine Fehlerdiagnose von Verbindungen durch Verbindungszeiten und SYN-Raten
Fazit
In diesem ersten Artikel sahen wir eine kurze Darstellung der TCP-Leistungsmetriken und wie das TCP-Protokoll die Verbindungen mit SYN/SYN + ACK/ACK-Paketen verarbeitet. Wir sehen auch einige häufige Fehlerfälle, die leicht mit PerformanceVision diagnostiziert werden können.
Um diese Art von Problemen zu beheben, verwendeten wir die Page Top Clients, Top Client Zones und Custom Charts. Um einen Schritt weiter zu gehen, haben wir "Advanced Filter: Unilateral Flows" verwendet, um Flows ohne Antworten zu filtern.Wir haben zudem mehrere Metriken vorgestellt: die Anzahl der ‚SYN‘ und ‚Handshakes‘ (Verbindungen), die SYN-Effizienz und die Verbindungszeit. In nächsten Artikel werden wir einen Blick darauf werfen, wie Sie eine Verbindung mit Reset- und Fin-Paketen beenden können.
In der Zwischenzeit; falls Sie es ausprobieren möchten, können Sie einfach unsere Evaluation Virtual Appliance herunterladen: