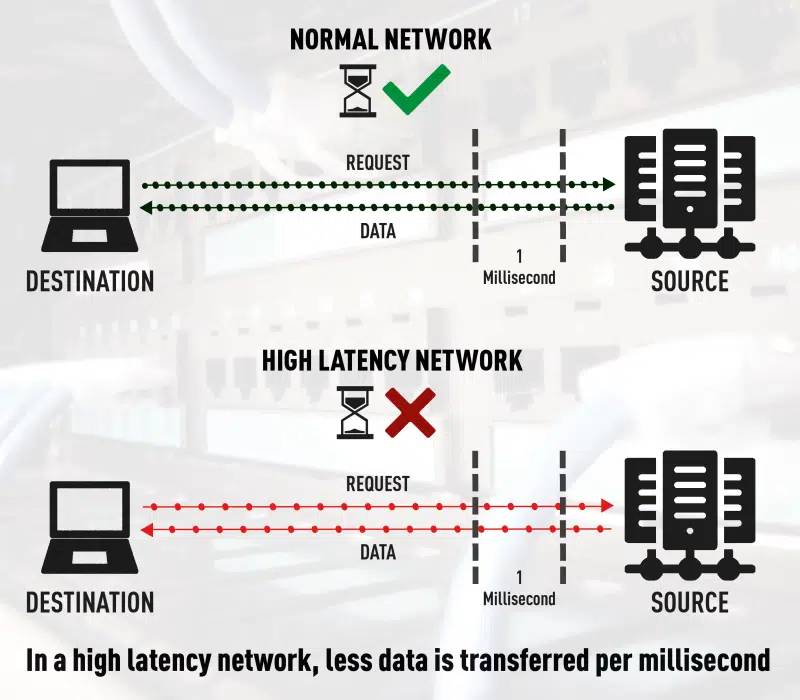
In meinem aktuellen Beitrag möchte ich auf das Thema Netzwerkzugriff mittels Netzwerk-TAP eingehen und Ihnen die Vorteile dieser Technik aufzeigen.
Netzwerke sind heutzutage das Kernelement für den Transport von Kommunikationsdaten und den Austausch von elektronischen Informationen. Die Zahl der netzwerkfähigen Produkte nimmt rapide zu und das Medium Internet ist längst zu einem festen Bestandteil unseres Lebens geworden.
Auch im Heimbereich setzen Hersteller mehr und mehr auf netzwerkfähige Elemente und ermöglichen dadurch den Anwendern einen ortsunabhängigen und komfortablen Zugriff (auf solche Geräte).
Ein Leben ohne Internet ist kaum noch denkbar und heutige Computer Netzwerke nehmen einen sehr großen Stellenwert ein.
Was aber, wenn das Netzwerk ausfällt
oder nicht in gewohnter Weise zur Verfügung steht?

Die Auswirkung eines Netzwerk Ausfalles kann gigantische finanzielle Folgen nach sich ziehen und durchaus ein weltweites Chaos auslösen.
Durch ein proaktives Monitoring System können Sie Ihre IT Dienstgüte kontinuierlich überwachen und somit das Risiko eines Ausfalles deutlich minimieren.
Eine permanente Überwachung Ihrer IT Infrastruktur hilft Ihnen auch bei Investitionsentscheidungen, da Sie über die gewonnenen Informationen detaillierte Analysen und Auswertungen erhalten und somit Tendenzen ableiten können. Gerade wenn es um Kapazitätsplanungen oder die Sicherstellung von QoS (Quality of Service) geht, ist ein umfangreiches Monitoring unumgänglich.
Ein Netzwerk Monitoring System ist kein Produkt von der Stange und in diesem Beitrag geht es um Netzwerk Monitoring durch das sogenannte „Packet Capture" Verfahren. Bei dieser Methode werden alle zu analysierenden Netzwerkdaten Byte für Byte ausgewertet. Dabei werden die übertragenen digitalen Informationen mittels Capturing aufgezeichnet und von dem Monitoring Tool analysiert.
Doch woher kommen diese Daten
und wie verlässlich sind diese Informationsquellen?
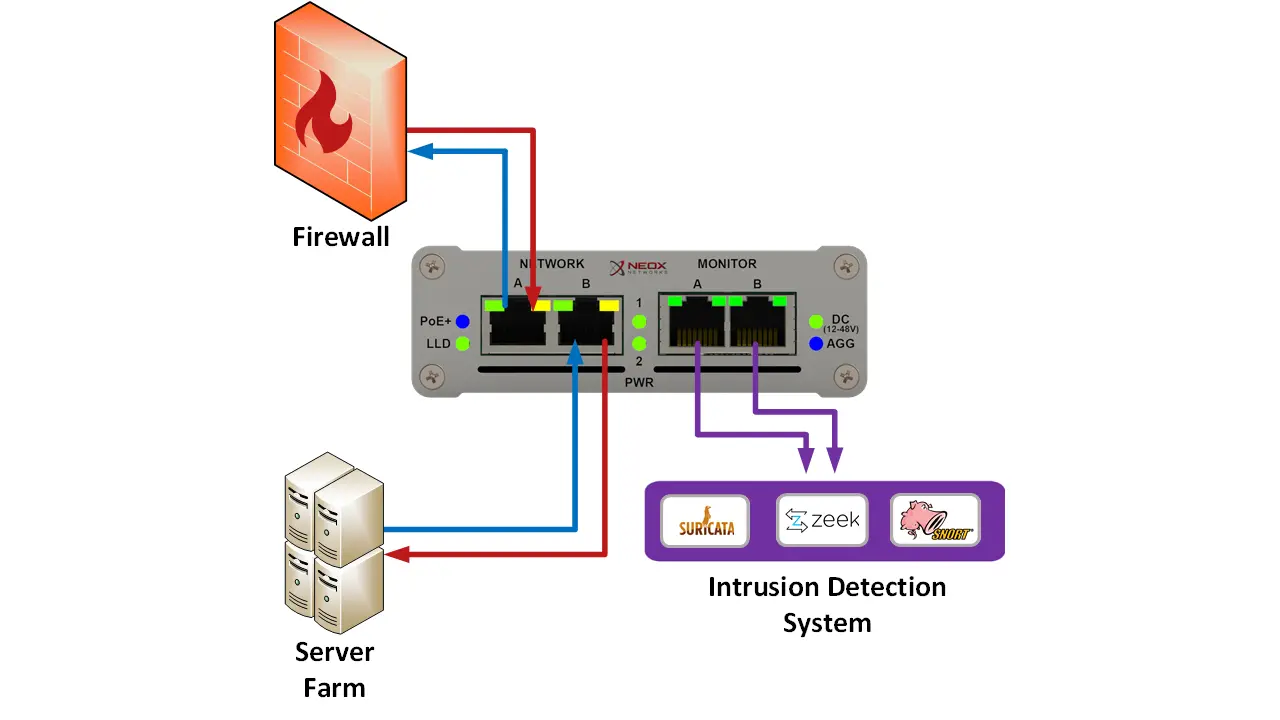
Am besten eignen sich für diese Messtechnik Netzwerk-TAPs. Was sind das für Geräte und wie werden diese eingesetzt?
Netzwerk-TAPs besitzen in der Regel vier physikalische Ports und werden transparent in die zu analysierende Netzwerkleitung eingeschleift. Dabei werden die auf den Netzwerk Ports übertragenen Informationen auf die Monitoring Interfaces gespiegelt.
Durch diese Technik bekommt man einen 100%’igen Einblick in das Netzwerk Geschehen und kann die Daten ohne Auswirkung auf die Netzwerk Performance analysieren. Da jedes einzelne übertragene Netzwerkpaket aus der Leitung herauskopiert wird, wäre man mit dieser Methode auch in der Lage, ein „Backup" seiner Netzwerkdaten anzulegen.
Technische Vorteile von Netzwerk-TAPs:
- Netzwerk-TAPs beeinträchtigen die Funktion der aktiven Netzwerkleitung keinesfalls
- 100% transparent und unsichtbar für Hacker und andere Angreifer
- Netzwerk-TAPs sind passiv und verhalten sich wie eine Kabelbrücke (fail-closed) im Fehlerfall
- Leiten die Netzwerkdaten vollständig aus
- Die Integrität der Daten ist gewährleistet
- Netzwerkpakete mit CRC Fehlern werden ebenso ausgeleitet
- 100% rückwirkungsfrei durch galvanische Trennung (Datendioden-Funktion)
- Nicht konforme Daten nach IEEE 802.3 werden herauskopiert
- Arbeitet protokollunabhängig und unterstützt Jumbo Frames
- Klassische Netzwerk-TAPs leiten die Daten im Voll-duplex Modus aus
- Überbuchung der Ausgangsports ausgeschlossen
- Keine lästige Konfiguration nötig, einmal installiert, liefert es die gewünschten Daten
- Fehler durch falsche Paketreihenfolge ausgeschlossen
- Konfigurationsfehler ausgeschlossen, da Inbetriebnahme durch Plug’n Play erfolgt
- Medienkonvertierende Netzwerk-TAPs erhältlich für größtmögliche Einsatzgebiete

Haben Sie Performance Probleme im Netzwerk oder bereits einen Ausfall, ist meist schnelles Handeln angesagt. In solchen Situation hat man wenig Zeit, um SPAN-Ports zu konfigurieren und möchte sofort mit dem Troubleshooting loslegen.
Was aber, wenn zu diesem Zeitpunkt kein SPAN-Port zur Verfügung steht oder das Passwort zum Switch gerade nicht zur Hand ist? Aber es kann auch noch viel schlimmer kommen, nämlich, dass der Switch durch einen DDoS Angriff oder eine bandbreitenintensive Anwendung ausgelastet ist und aufgrund dessen eine Analyse am SPAN-Port quasi unmöglich ist. Auch könnte es passieren, dass der Switch durch einen böswilligen Angriff nicht in gewohnter Weise zur Verfügung steht.
Gerade aus Sicherheitsgründen oder um Wirtschaftsspionage zu ermitteln, sind Netzwerk-TAPs unerlässlich, da Sie auf physikalischer Ebene die Daten, gleichgültig was im Netzwerk passiert, ausleiten und somit stets eine zuverlässige Netzwerkanalyse und Monitoring erlauben.
Anwendungsbeispiele von Netzwerk-TAPs:
- Proaktives Netzwerk-Monitoring
- Kapazitätsplanung Fiber-Netzwerk-TAP
- Base Lining (Trend Analyse)
- Security und Forensik
- Netzwerkanalyse und Troubleshooting
- Netzwerk und Application Performance Analyse
- Lawful Interception (gesetzeskonforme Überwachung)
- SLA Monitoring
- Compliance Monitoring
- Database Monitoring
Fazit
Es gibt viele Gründe, Netzwerk-TAPs gegenüber dem SPAN-Port zu priorisieren und wir hoffen, dass wir Ihnen in diesem Artikel einen Überblick über die Vorzüge näherbringen konnten.