
Es ist noch nicht so lange her, dass Unternehmen ihre kritischen Geschäftsanwendungen ausschließlich in eigenen Netzwerken von Servern und Client-PCs untergebracht haben. Die Überwachung und Fehlerbehebung von Leistungsproblemen, wie zum Beispiel der Latenz, war einfach umzusetzen.
Obwohl sich Tools zur Netzwerküberwachung und Diagnose stark verbessert haben, hat die Einführung einer Vielzahl von miteinander verbundenen SaaS-Anwendungen und Cloud-gehosteten Diensten die typische Netzwerkkonfiguration stark verkompliziert, was negative Auswirkungen haben kann.
Da Unternehmen immer mehr Anwendungen und Datenhosting an externe Anbieter outsourcen, führt dies immer schwächere Links in das Netzwerk ein. SaaS-Dienste sind im Allgemeinen zuverlässig, aber ohne eine dedizierte Verbindung können sie nur so gut sein, wie die Internetverbindung, die sie verwenden.
Aus Sicht des Netzwerkmanagements besteht das sekundäre Problem bei extern gehosteten Apps und Services darin, dass das IT-Team weniger Kontrolle und Transparenz hat, was es schwieriger macht, dass Dienstleistungsanbieter im Rahmen ihrer Dienstleistungsvereinbarungen (SLAs) bleiben.
Die Überwachung des Netzwerkverkehrs und die Fehlerbehebung innerhalb der relativ kontrollierten Umgebung einer Unternehmenszentrale, ist für die meisten IT-Teams zu bewältigen.
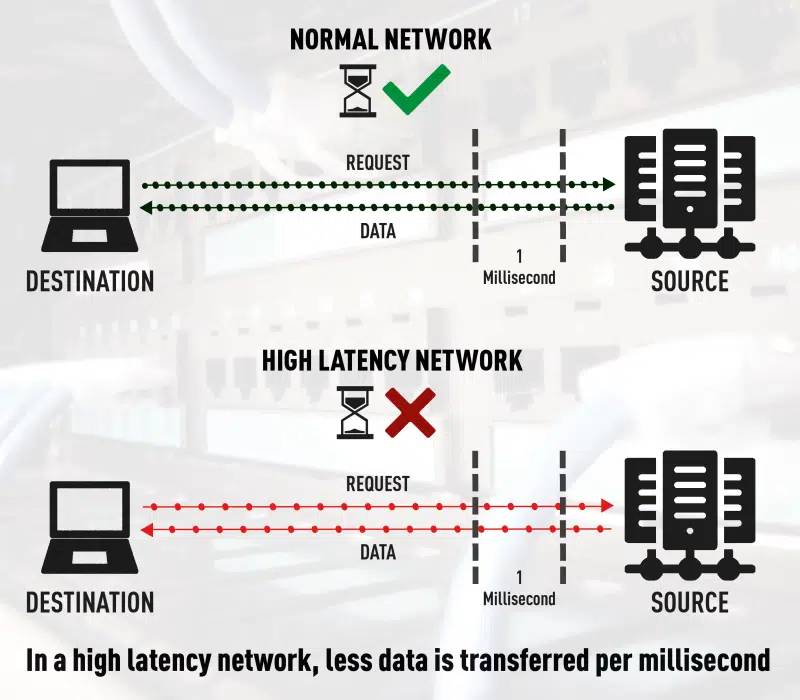
Aber für Organisationen, die auf einem verteilten Geschäftsmodell beruhen, mit mehreren Zweigstellen oder Mitarbeitern an entfernten Standorten, führt die Verwendung dedizierter MPLS-Leitungen schnell zu hohen Kosten.
Wenn Sie bedenken, dass der Datenverkehr von Anwendungen wie Salesforce, Skype for Business, Office 365, Citrix und anderen, in der Regel den Hauptgeschäftssitz umgehen, ist es nicht verwunderlich, dass Latenz immer häufiger auftritt und immer schwieriger zu beheben ist.
Einer der ersten Opfer der Latenz ist die VoIP-Anrufqualität, die sich in unnatürlichen Verzögerungen bei Telefongesprächen manifestiert. Mit dem explosionsartigen Wachstum von VoIP und anderen UCaaS-Anwendungen wird dieses Problem jedoch weiter zunehmen.
Ein weiterer Bereich, in dem die Latenz ihren Tribut fordert, sind Datenübertragungsgeschwindigkeiten. Dies kann zu einer Reihe von Problemen führen, insbesondere wenn große Datendateien oder medizinische Aufzeichnungen von einem Ort zu einem anderen übertragen oder kopiert werden.
Auch bei großen Datentransaktionen, wie einer Datenbankreplikation, kann die Latenz ein Problem darstellen, da mehr Zeit für die Durchführung von Routineaktivitäten erforderlich ist.
Auswirkungen von dezentralisierten Netzwerken und SaaS
Bei so vielen Verbindungen zum Internet, von so vielen Standorten aus, macht es Sinn, dass die Leistungsüberwachung von Unternehmensnetzwerken aus dem Datenzentrum heraus erfolgt. Einer der besten Ansätze besteht darin, Tools zu finden, welche die Verbindungen an allen Remote-Standorten überwachen.
Die meisten von uns verwenden fast täglich Anwendungen wie Outlook, Word und Excel. Wenn wir Office 365 verwenden, sind diese Anwendungen wahrscheinlich so konfiguriert, dass sie sich mit Azure verbinden und nicht mit dem Unternehmensdatencenter.
Wenn das IT-Team die Netzwerkleistung nicht direkt in der Zweigstelle überwacht, verliert es die User Experience (UX) an diesem Standort vollständig aus den Augen. Sie denken vielleicht, dass das Netzwerk gut funktioniert, während die Benutzer tatsächlich wegen eines bislang nicht diagnostizierten Problems frustriert sind.
Wenn Datenverkehr von SaaS-Anbietern und anderen cloudbasierten Speicheranbietern von und zu einem Unternehmen weitergeleitet wird, kann dies durch Jitter, Trace-Route und manchmal auch Rechengeschwindigkeit negativ beeinträchtigt werden.
Dies bedeutet, dass Latenz für die Endbenutzer und Kunden zu einer sehr ernsthaften Einschränkung wird. Die Zusammenarbeit mit Anbietern, die sich in der Nähe der benötigten Daten befinden, ist eine Möglichkeit, um potenzielle Probleme aufgrund von Entfernungen zu minimieren. Aber selbst in einem parallelen Prozess haben Sie möglicherweise Tausende oder Millionen von Verbindungen, die versuchen auf einmal durchzukommen. Dies führt zwar zu einer eher geringen Verzögerung, jedoch bauen sie sich auf und werden über weite Distanzen immer größer.

Ist maschinelles Lernen die Antwort
auf eine hohe Netzwerklatenz?
Früher war es so, dass jedes IT-Team klare Netzwerkpfade zwischen seinem Unternehmen und Rechenzentrum definieren und überwachen konnte. Sie konnten Anwendungen steuern und regulieren, die auf internen Systemen ausgeführt wurden, da alle Daten lokal installiert und gehostet wurden, ohne auf die Cloud zuzugreifen.
Dieses Kontrollniveau ermöglichte einen besseren Einblick in Probleme wie Latenz und ermöglichte es ihnen eventuell auftretende Probleme schnell zu diagnostizieren und zu beheben.
Fast zehn Jahre später hat die Verbreitung von SaaS-Anwendungen und Clouddiensten nun die Leistungsdiagnostik von Netzwerken so kompliziert gemacht, dass neue Maßnahmen erforderlich sind.
Was ist die Ursache für diesen Trend? Die einfache Antwort ist eine zusätzliche Komplexität, Distanz und mangelnde Sichtbarkeit. Wenn ein Unternehmen seine Daten oder Anwendungen an einen externen Anbieter überträgt, anstatt sie lokal zu hosten, fügt dies effektiv eine dritte Partei in den Mix der Netzwerkvariablen ein.
Jeder dieser Punkte führt zu einer potenziellen Schwachstelle, die sich auf die Netzwerkleistung auswirken kann. Diese Dienste sind zwar größtenteils recht stabil und zuverlässig, aber Ausfälle bei einem oder mehrerer Dienste kommen selbst bei den Branchengrößten vor und können sich auf Millionen von Benutzern auswirken.
Tatsache ist, dass es viele Variablen in einer Netzwerklandschaft gibt, die von den IT-Teams der Unternehmen nicht mehr kontrolliert werden können.
/p>Eine Möglichkeit, mit der Unternehmen versuchen die Leistung sicherzustellen, besteht darin, einen dedizierten MPLS-Tunnel zu nutzen, welcher zur eigenen Unternehmenszentrale oder ins Datenzentrum führt. Aber dieser Ansatz ist teuer und die meisten Unternehmen nutzen diese Methode nicht für ihre Zweigstellen. Dies hat zur Folge, dass Daten aus Anwendungen wie Salesforce, Slack, Office 365 und Citrix nicht mehr durch das Rechenzentrum des Unternehmens übertragen werden, da sie dort nicht mehr gehostet werden.
Bis zu einem gewissen Grad kann die Latenz durch die Verwendung traditioneller Methoden zur Überwachung der Netzwerkleistung gemindert werden, aber eine Latenz ist naturgemäß nicht vorhersehbar und schwer zu verwalten.
Wie sieht es jedoch mit künstlicher Intelligenz aus? Wir alle haben Beispiele von Technologien gehört, die große Fortschritte machen, indem sie eine Form des maschinellen Lernens verwenden. Leider sind wir jedoch nicht an dem Punkt, an dem maschinelle Lernverfahren die Latenz signifikant minimieren können.
Wir können nicht genau vorhersagen, wann ein bestimmter Switch oder Router mit Datenverkehr überlastet wird. Das Gerät kann einen plötzlichen Datenburst erleben, der nur eine Verzögerung von einer Millisekunde oder sogar zehn Millisekunden verursacht. Tatsache ist, sobald diese Geräte überlastet sind, kann das maschinelle Lernen bei diesen plötzlichen Änderungen noch nicht helfen, Warteschleifen von Paketen, die auf eine Verarbeitung warten, zu verhindern.
Die zur Zeit effektivste Lösung besteht darin, die Latenz dort zu bekämpfen, wo sie die Benutzer am meisten beeinflusst – so nah wie möglich an ihrem physischen Standort.
In der Vergangenheit nutzten die Techniker Netflow und/oder eine Vielzahl von Überwachungsinstrumenten im Rechenzentrum, da sie genau wussten, dass der Großteil des Datenverkehrs zu ihrem Server gelangte und dann zu ihren Kunden zurückkehrte. Bei einer so viel größeren Datenverteilung gelangt heute nur ein kleiner Teil der Daten zu den Servern, was eine Überwachung des eigenen Datenzentrums weit weniger effizient macht.
Anstatt sich ausschließlich auf ein solches zentralisiertes Netzwerküberwachungsmodell zu verlassen, sollten IT-Teams ihre herkömmlichen Tools ergänzen, indem sie die Datenverbindungen an jedem Remote-Standort oder in jeder Zweigstelle überwachen. Im Vergleich zu heutigen Praktiken ist dies eine veränderte Denkweise, aber sie macht Sinn: Wenn die Daten verteilt werden, muss auch die Netzwerküberwachung verteilt werden.
Anwendungen wie Office 365 und Citrix sind gute Beispiele, da die meisten von uns regelmäßig Produktivitäts- und Unified Communications Tools verwenden. Diese Anwendungen werden wahrscheinlich eher mit Azure, AWS, Google oder anderen verbunden, als mit dem eigenen Unternehmensdatencenter. Wenn das IT-Team diese Zweigstelle nicht aktiv überwacht, verliert es die User Experience an diesem Standort vollständig aus den Augen.
Wählen Sie einen umfassenden und geeigneten Ansatz
Trotz aller Vorteile von SaaS-Lösungen wird die Latenz auch weiterhin eine Herausforderung bleiben, falls IT-Teams von Unternehmen ihre Herangehensweise an das Netzwerkmanagement nicht überdenken.
Kurz gesagt, sie müssen einen umfassenden, dezentralisierten Ansatz für die Netzwerküberwachung verfolgen, der das gesamte Netzwerk und all seine Zweigstellen umfasst. Es müssen ebenfalls bessere Möglichkeiten gefunden werden, die User Experience zu überwachen und bei Bedarf zu verbessern.
Fokussieren Sie sich auf die User Experience
Es besteht kein Zweifel, dass die Verbreitung von SaaS-Tools und Cloud-Ressourcen für die meisten Unternehmen ein Segen war. Die Herausforderung für die IT-Teams besteht jetzt jedoch darin, den Ansatz des Netzwerkmanagements in einem dezentralisierten Netzwerk zu überdenken. Ein wichtiges Thema ist sicherlich die Fähigkeit, effektiv zu überwachen, dass SLAs (Dienstleistungsvereinbarungen) eingehalten werden. Noch wichtiger ist jedoch die Möglichkeit, die Servicequalität für alle Endbenutzer sicherzustellen.
Um das zu erreichen, müssen IT-Experten genau sehen, was die Nutzer in Echtzeit erleben.
Dieser Übergang zu einem proaktiveren Überwachungs- und Fehlerbehebungsstil hilft IT-Fachleuten bei der Behebung von Netzwerk- oder Anwendungsengpässen jeglicher Art, bevor sie für Mitarbeiter oder Kunden problematisch werden.
Fazit
Ergo, um möglichst niedrige Latenzen und eine damit einhergehende optimale User Experience sicherzustellen reicht ein auf zentralen Messpunkten basierendes Monitoring heutzutage meist nicht mehr aus.
Während das Monitoring nach wie vor zentralisiert bleiben kann müssen die Messpunkte zunehmend dezentralisiert werden.