How to save monitoring resources with Packet Slicing
and comply with legal requirements
Problem

Often the gap between the capacity of the recording analysis system on the one hand and the amount of incoming data on the other is so large that without appropriate additional mechanisms the analysis system is most likely not able to record all individual packets without loss.
Depending on the purpose of the analysis system, this is a major problem, as every packet counts, especially in the cyber security environment, and otherwise it is not possible to ensure that all attacks and their effects are detected.
Attacks that are not detected in time or even remain completely invisible can cause enormous damage to companies, even leading to recourse claims from possible insurers if they discover that their clients did not fulfil their duty of care.
But how does such a situation arise? It can happen very quickly that networks in companies grow, often in parallel with the business development of this company, while the often already existing analysis and monitoring systems, planned with reserves during procurement, reach the end of their reserves more and more often.
Higher bandwidths, more and more services and interfaces used in the LAN reduce the capacities to the point where the systems can no longer keep up and have to discard packets.

From this moment on, it is theoretically possible for an attacker to stay undetected in the local network, as the analysis system is hopelessly overloaded. The administrator is no longer able to see which parties in his network are talking to each other, which protocols they are using and which endpoints are being communicated with outside the LAN.
Often, however, it is not capacity problems that trigger the activation of Packet Slicing, but rather data protection reasons. Depending on where and which data is tapped and when, it may be obligatory for the company to only record and evaluate data that does not contain any personal or performance-related information.
While typically the packet header only contains connection data (WHEN, WHO, HOW, WHERE), the payload data, although usually encrypted, contains the very content data that theoretically makes it possible to measure the performance of individual users. Depending on the place of use, however, this is often neither wanted nor allowed. It must therefore be ensured that it is not possible for the administrator to reconstruct personal information from the recorded data.
Reduce analysis data by means of Packet Slicing

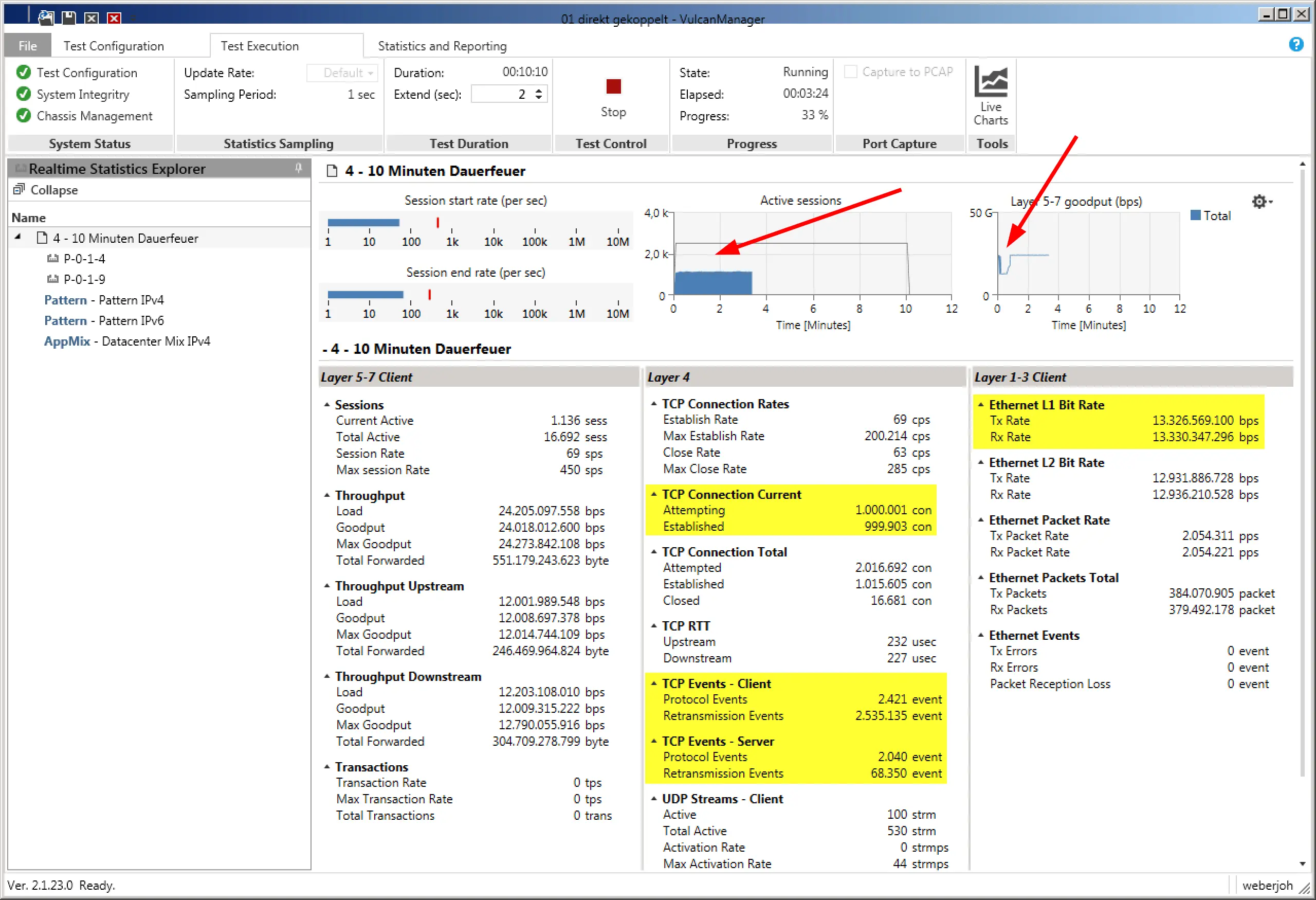
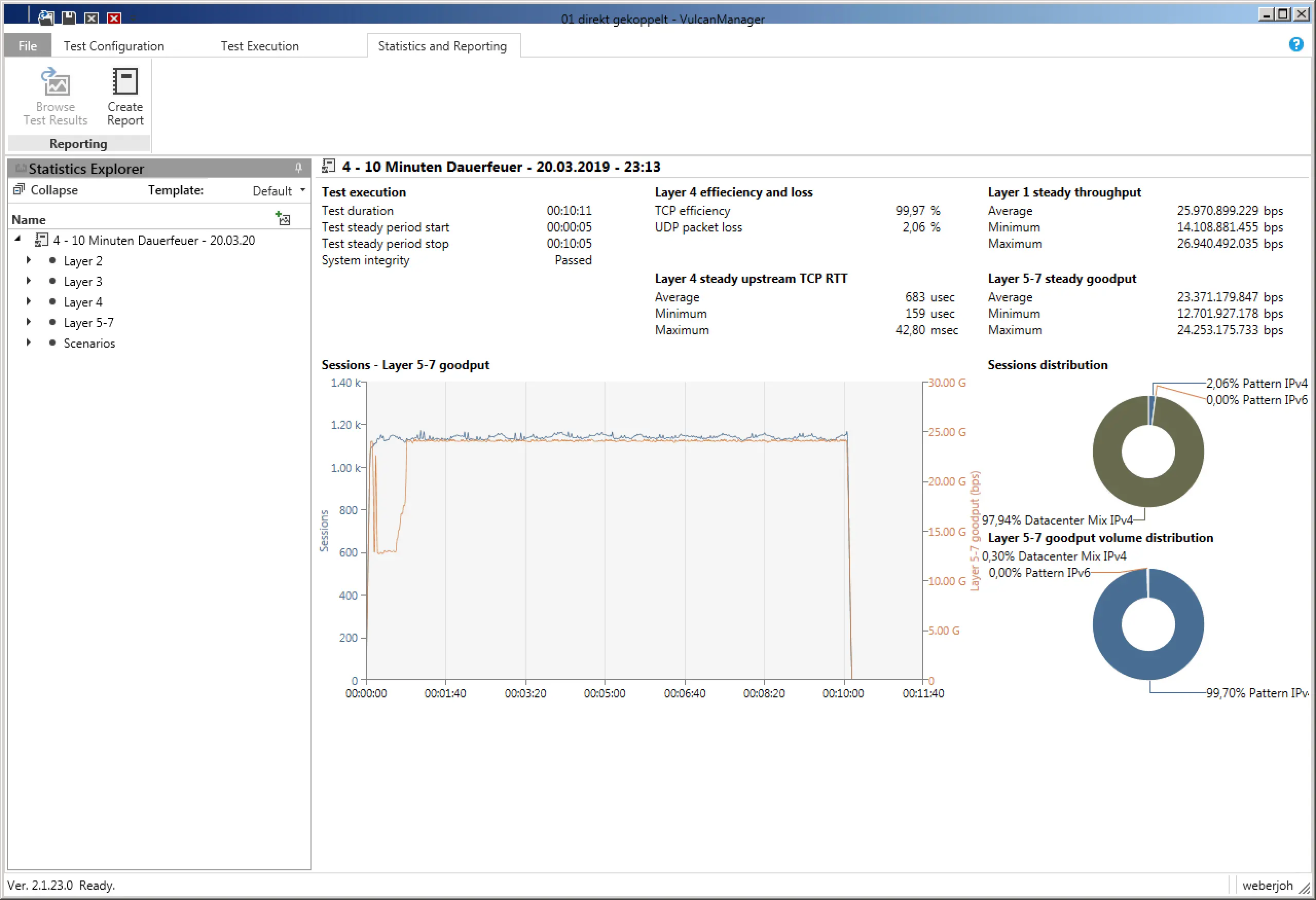
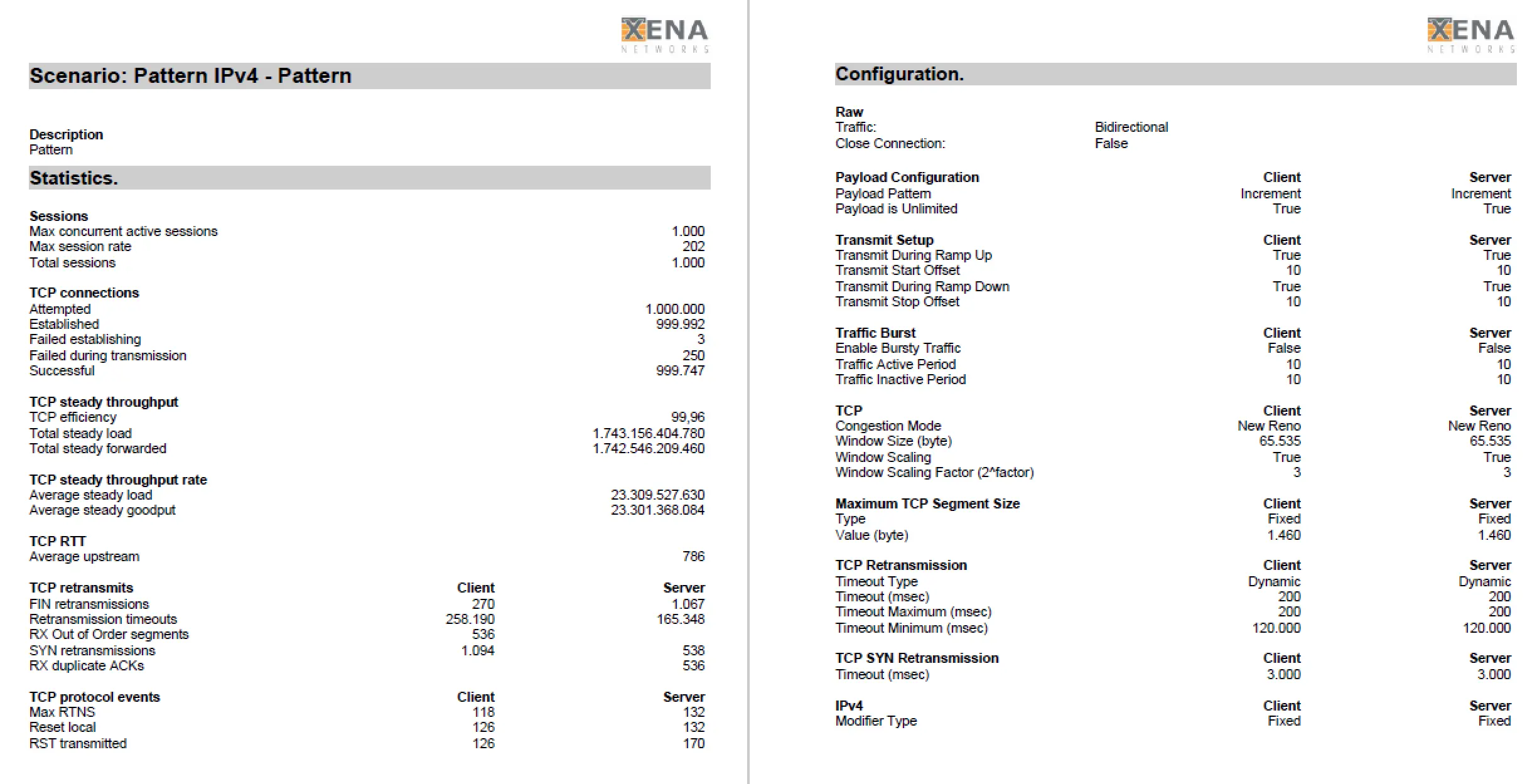
And this is exactly where the “Packet Slicing” feature comes into play: with this procedure it is possible to reduce the incoming data load on your analysis system by up to 87% (with 1518 bytes packet size and Packet Slicing at 192 bytes) by simply removing the user data from each packet.
Many analysis and monitoring approaches only need the information stored in the packet header, i.e. the metadata, for their evaluations and analyses, while the user data often does not contain any important or usable information, as this is usually encrypted anyway and thus cannot be used for the evaluation.
By removing the user data, a massive relief of the processing instance is to be expected, and in some cases this enables even greater coverage of the LAN by the monitoring and analysis device.
FCS Checksum Problem

An important aspect of Packet Slicing is the recovery of the FCS checksum of each modified packet. Since the structure and length of the packet is affected by cutting away the user data, the originally calculated checksum, which was calculated by the sender and entered in the FCS field of the packet header, is no longer correct.
As soon as such a packet arrives on the analysis system, those packets are discarded or declared erroneous, as the checksum in the FCS field is still based on the original packet length. To counteract this, it is essential that the FCS checksum is recalculated and also entered for each packet from which the user data has been removed, as this would otherwise force the analysis systems to classify these packets as faulty and/or manipulated.
Network Packet Broker as a Packet Slicer
In general, there are several possibilities where the above-mentioned Packet Slicing can be activated in the visibility platform used by the customer. On the one hand, this is a case-by-case decision, on the other hand, it is also a technical one.

Assuming that the user has set several measuring points distributed in his network, a Network Packet Brokeris often used. This device is another level of aggregation and is typically used as the last instance directly before the monitoring system. A Network Packet Broker is optically very close to a switch and enables the user to centrally combine the data from multiple measuring points (Network TAPs or SPAN ports) and send them aggregated in one or more data streams to the central analysis system.
Thus, for example, the data from 10 distributed measuring points set in 1 Gigabit lines can be sent to an analysis system with a single 10 Gigabit port by the Network Packet Broker aggregating these 1 Gigabit signals and outputting them again as a single 10 Gigabit signal.
 At this point, however, the user learns of a catch to the whole issue: often the analysis systems, although equipped with a 10Gigabit connection, are not able to process bandwidths of 10Gigabit/second as well.
At this point, however, the user learns of a catch to the whole issue: often the analysis systems, although equipped with a 10Gigabit connection, are not able to process bandwidths of 10Gigabit/second as well.
This can have a variety of reasons, which, however, should not be the subject of this blog entry. However, the initial situation is predestined for the use of Packet Slicing; while one would normally have to expand one’s monitoring infrastructure at immense cost, by switching on Packet Slicing one can massively reduce the incoming flood of data and thus continue to use one’s existing systems; all that is needed is a corresponding instance with precisely this feature, which usually costs only a fraction of what would be estimated for an upgrade of the analysis systems.
Analysis Systems as Packet Slicers
 Another possibility is offered to the user on the analysis systems themselves. Depending on the manufacturer, structure and components used, it is possible to directly remove the user data on the systems themselves and recalculate the checksum before the packets are passed on internally to the corresponding analysis modules.
Another possibility is offered to the user on the analysis systems themselves. Depending on the manufacturer, structure and components used, it is possible to directly remove the user data on the systems themselves and recalculate the checksum before the packets are passed on internally to the corresponding analysis modules.
In the vast majority of cases, an FPGA-based network card is required for this, as it must be ensured that no CPU-based resource is used to modify each individual packet. Only by means of pure hardware capacities can the user be sure that every packet is really processed accordingly; any other approach could again lead to the errors and problems mentioned at the beginning.
Packet Slicing to meet Legal Requirements
 Another aspect worth mentioning is the fulfilment of legal requirements. Especially in the context of the GDPR, it may be necessary to remove the user data, as often the metadata is sufficient for an analysis.
Another aspect worth mentioning is the fulfilment of legal requirements. Especially in the context of the GDPR, it may be necessary to remove the user data, as often the metadata is sufficient for an analysis.
For example, if you want to analyse VoIP, you can use Packet Slicing to ensure that unauthorised persons cannot listen to the conversation, but you can still technically evaluate the voice transmission and examine it for quality-of-service features. This allows performance values to be evaluated, privacy to be protected and legal requirements such as the GDPR to be met.
Conclusion
So we see that there are indeed different ways to distribute the final load on the analysis and monitoring systems or even, as in this example, to reduce it without losing the most important information for creating performance charts, top talkers and more. Packet Slicing is therefore a valid solution for the user, which can be easily implemented in almost all cases and achieves usable results.