Napatech
Hochperformante FPGA-basierte SmartNICs/Netzwerkkarten






Entwickelt für 100% Packet Capture und Analyse
Die Napatech Karte ermöglicht es Ihnen, Daten aus verschiedenen Ports in einen zeitlich geordneten Analyse-Datenstrom zusammenzuführen. Es unterstützt 1 – 128 Paketströme und verwendet eine auf Hardware gestützte intelligente Flow-Verteilung, damit Ihre Anwendung auch höhere Paketraten ohne Paketverlust verarbeiten kann. Eine Umverteilung der Daten kann Flow-basierend oder auf L3/L4-Filterkriterien stattfinden.
PERFEKTE LEISTUNGFür jede Verbindungsgeschwindigkeit zu jeder Zeit |
KOMPLETTES PORTFOLIOVon 1G – 200G |
PLUG & PLAYSofort einsatzbereite Lösung |
SCALE INSIDEMehrere Netzwerkkarten in einem Server |
SCALE OUTSIDESynchronisierung mehrerer Server |
LEISTUNGSFÄHIGMaximiere die Leistung deiner Anwendung |
LINEARVoller Durchfluss ohne Paketverlust |
UNTERSCHIEDLICHE GESCHWINDIGKEITENMehrere Geschwindigkeiten in einem Server |
BÜNDEL – APPLIKATIONENEffizientere Servernutzung |
Features
Komplette Paketerfassung bei maximalen Leitungsgeschwindigkeiten
|
Napatech’s Netzwerkkarten sind hochoptimiert, um den Netzwerkverkehr auch bei voller Leitungsgeschwindigkeit zu erfassen, mit einer äußerst geringen CPU-Belastung auf dem Hostserver. Eine verlustfreie Paketerfassung (Capturing) ist entscheidend für Applikationen, welche den gesamten Netzwerkverkehr analysieren müssen. Sollte irgendetwas verworfen werden müssen, trifft die Anwendung diese Entscheidung, weshalb dies letztendlich nicht eine Beschränkung der Netzwerkkarten sein darf. Standard verbaute Netzwerkkarten (NICs) sind nicht für Analyseanwendungen ausgelegt, welche den gesamten Datenverkehr einer Verbindung oder eines Links analysieren. Normale NICs sind von Ihrer Funktionsweise auf nur für eine Kommunikation konzipiert, bei denen die Netzwerkdaten, die nicht an den Absender oder Empfänger adressiert sind, einfach verworfen werden. Dies zeigt, dass NICs nicht in der Lage sind Datenmengen zu verarbeiten, die kontinuierlich in Bursts auf Ethernet-Verbindungen auftreten. In diesen genannten Situationen wird die vollständige Bandbreite einer Verbindung genutzt, was wiederum die Fähigkeit voraussetzt, alle Ethernet-Frames zu analysieren. Napatech’s Netzwerkkarten wurden speziell für diese Aufgabe konzipiert und bieten eine maximal mögliche Kapazität für eine kompromisslose Aufzeichnung von Netzwerkdaten. |
Multi-Port Paketsequenz und Zusammenführung
 |
Napatech’s Netzwerkkarten bieten in der Regel mehrere Ports an. Die Ports sind in der Regel gepaart, wobei in der Regel ein Port Upstream-Pakete und der andere Port Downstream-Pakete empfängt. Da diese beiden Streams, die in verschiedene Richtungen laufen, als Einheit analysiert werden müssen, ist es notwendig die Pakete von beiden Ports, zu einem einzigen Analysestrom zusammenzuführen. Napatech’s FPGA-basierte Netzwerkkarten können mit Hilfe von präzisen Zeitstempeln eines jeden Ethernet-Frames, die auf mehreren Ports in der Hardware empfangen werden, alle Pakete sequenzieren und in der richtigen Reihenfolge zusammenführen. Dies ist sehr effizient und erleichtert eine wichtige und kostspielige Aufgabe der Analyseanwendung. Es gibt einen wachsenden Bedarf an Analysegeräten, die in der Lage sind, mehrere Punkte im Netzwerk sowohl zu überwachen als auch zu analysieren, und sogar eine netzwerkweite Sichtbarkeit zu liefern. Dies erfordert nicht nur, dass mehrere Netzwerkkarten in einer einzigen Appliance installiert werden müssen, sondern es erfordert auch, dass die Analysedaten aller Ports auf jeder Karte korreliert werden. Mit der Napatech Software Suite ist es möglich, die Analysedaten von mehreren Netzwerkkarten zu einem einzigen Analysestrom zusammenzuführen. Diese Korrelation basiert auf den Zeitstempeln eines jeden Ethernet-Frames mit einer Genauigkeit im Nanosekundenbereich und ermöglicht so eine zeitlich geordnete Zusammenführung einzelner Datenströme. |
Intelligente Multi-CPU Verteilung
 |
Moderne Server bieten eine noch nie da gewesene Rechenleistung durch Multi-Core-CPU-Implementierungen. Dies macht standardmäßige Server zu einer idealen Plattform für die Geräteentwicklung. Um die Verarbeitungsleistung von modernen Servern voll auszuschöpfen, ist es wichtig, dass die Analyseanwendung ebenfalls Multi-Threading unterstützt und die richtigen Ethernet-Frames dem richtigen CPU-Kern für eine Verarbeitung zur Verfügung gestellt werden. Allerdings müssen auch die Frames zur richtigen Zeit bereitgestellt werden, um sicherzustellen, dass die Analyse in Echtzeit durchgeführt werden kann. Die Napatech Multi-CPU Verteilung wird aus unseren umfangreichen Kenntnissen der Serverarchitektur und den tatsächlichen Erfahrungen unserer Kunden aufgebaut und optimiert. Napatech’s Netzwerkkarten gewährleisten, dass identifizierte Daten-Streams von verwandten Ethernet-Frames optimal auf die verfügbaren CPU-Kerne verteilt werden. Dadurch wird sichergestellt, dass die Verarbeitungslast über die vorhandenen Verarbeitungsressourcen ausgeglichen wird und dass die richtigen Frames von den richtigen CPU-Kernen verarbeitet werden. Mit der Flow-Verteilung auf mehrere CPU-Kerne kann die Durchsatzleistung der Analyseanwendung linear mit der Anzahl der Kerne (bis zu 128) erhöht werden. Des Weiteren kann auch die Leistung durch schnellere Prozessorkerne skaliert werden. Dieser hochflexible Mechanismus ermöglicht viele verschiedene Wege, um eine Lösung zu entwerfen und bietet die Möglichkeit, Kosten und/oder Leistung zu optimieren. Napatech’s Karten unterstützen unterschiedliche Verteilungsarten, die vollständig konfigurierbar sind:
|
Hardware Timestamp
 |
Die Fähigkeit, die genaue Zeit festzustellen, wann Frames erfasst wurden, ist für viele Anwendungen kritisch und entscheidend. Um dies zu ermöglichen, besitzen alle Napatech Netzwerkkarten die Fähigkeit, für jeden erfassten und übertragenen Frame einen hochpräzisen Zeitstempel bereitzustellen, der mit einer 1 Nanosekunden-Auflösung durch die Hardware gestempelt wird. Bei 10 Gbit/s kann ein Ethernet-Frame alle 67 Nanosekunden übertragen werden. Bei 100 Gbps wird diese Zeit auf 6,7 Nanosekunden reduziert. Aus diesem Grund sind Zeitstempel mit einer Genauigkeit im Nanosekundenbereich notwendig, um eindeutig zu identifizieren, wann ein Frame empfangen wird. Diese unglaubliche Präzision ermöglicht es Ihnen auch, Frames von mehreren Ports auf mehreren Beschleunigern zu einem einzigen, zeitlich geordneten Analysestrom zusammenzuführen. Um einwandfrei in den verschiedenen Betriebssystemen arbeiten zu können, unterstützen Napatech’s Netzwerkkarten eine Vielfalt von branchenüblichen Zeitstempelformaten und bieten zudem eine Reihe von Lösungen für unterschiedliche Anwendungsarten. 64-Bit-Zeitstempelformate:
|
Optimale Cachenutzung
 |
Napatech’s Capture Karten verwenden eine Pufferstrategie, die eine Anzahl von umfangreichen Speicherpuffern bereitstellt, bei der so viele Netzwerkpakete wie möglich nacheinander in jedem Puffer platziert werden. Bei dieser Implementierung wird nur der erste Zugriff auf ein Paket im Puffer durch die Zugriffszeit auf den externen Speicher beeinflusst. Dank einem Pre-Fetch des Pufferspeichers sind die nachfolgenden Pakete bereits im Level 1 Cache, bevor die CPU sie benötigt. Da Hunderte oder sogar Tausende von Paketen in einen Puffer platziert werden können, kann eine sehr hohe CPU-Cacheleistung erreicht werden, was zu einer Anwendungsbeschleunigung führt. Die Pufferkonfiguration kann einen dramatischen Einfluss auf die Leistungsfähigkeit von Analyseanwendungen haben. Verschiedene Anwendungen haben unterschiedliche Anforderungen, wenn es um Latenz oder Verarbeitung geht. Es ist daher äußerst wichtig, dass die Anzahl und Größe der Puffer für die jeweilige Anwendung optimiert werden kann. Napatech’s Netzwerkkarten machen dies möglich. Die flexible Pufferstruktur der Server, die von Napatech’s Karten unterstützt wird, kann für unterschiedliche Applikationsanforderungen optimiert werden. Zum Beispiel können Frames in kleineren Einheiten an Anwendungen übermittelt werden, die eine kurze Latenz benötigen, wahlweise mit einer festen maximalen Latenzzeit. Anwendungen ohne Latenzanforderungen können von Daten profitieren, die in größeren Einheiten übermittelt werden, was eine effektivere CPU-Verarbeitung der Server ermöglicht, weil die Daten bereits verfügbar sind. Applikationen, welche Informationen korrelieren müssen, die über Pakete verteilt sind, können größere Serverpuffer (bis zu 128 GB) konfigurieren. Bis zu 128 Puffer können konfiguriert und mit der Multi-CPU-Verteilung von Napatech kombiniert werden (siehe „Multi-CPU-Verteilung“). |
Integrierte Paketpufferung
|
|
Napatech’s Netzwerkkarten besitzen einen eingebauten Speicher für die Pufferung von Ethernet-Frames. Eine Pufferung gewährleistet eine garantierte Zustellung von Daten, auch wenn bei der Übermittlung der Daten an die Anwendung eine Überlastung vorliegt. Es gibt drei potenzielle Überlastungsquellen: die PCI-Schnittstelle, die Serverplattform und die Analyseanwendung. PCI-Schnittstellen bieten eine festgelegte Bandbreite für die Übertragung von Daten vom Beschleuniger zur Anwendung. Dies begrenzt die Datenmenge, die kontinuierlich aus dem Netzwerk in die Anwendung übermittelt werden kann. Beispielsweise kann eine 16-spurige PCIe Gen3-Schnittstelle bis zu 115 Gbit/s an Daten zur Anwendung übermitteln. Sollte hingegen die Netzwerkgeschwindigkeit 2 × 100 Gbit/s betragen, kann ein Daten-Burst nicht über die PCIe Gen3-Schnittstelle in Echtzeit übermittelt werden, da die Übertragungsrate die doppelte maximale PCIe-Bandbreite überschreitet. In diesem Fall kann die integrierte Paketpufferung der Napatech Karte den Burst aufnehmen und gewährleistet, dass keine Daten verloren gehen und gibt die Frames wieder frei, wenn die Anwendung Kapazitäten zur Verfügung stellt. Server und Anwendungen können so konfiguriert sein, dass eine Überlastung in der Infrastruktur der Server oder sogar in der Anwendung selbst auftritt. Ebenfalls können die CPU-Kerne mit der Verarbeitung oder dem Abrufen von Daten von entfernten Caches und Speicherorten beschäftigt sein, was dazu führt, dass neue Ethernet-Frames nicht ordnungsgemäß von Standard Netzwerkkarten übertragen werden können. Darüber hinaus kann die Anwendung mit nur einem oder einigen Verarbeitungs-Threads konfiguriert werden, was dazu führen kann, dass die Anwendung überlastet wird, sodass neue Ethernet-Frames nicht übertragen werden. Über eine integrierte Paketpufferung können die Ethernet-Frames zwischengespeichert werden, bis der Server oder die Anwendung in der Lage ist, diese zu empfangen. Dadurch wird sichergestellt, dass keine Ethernet-Frames verloren gehen und dass kompromisslos alle Netzwerkdaten für eine Analyse zur Verfügung gestellt werden. |

Tunneling-Unterstützung
 |
In Mobilfunknetzen wird der Internetverkehr von jedem Teilnehmer über GTP (GPRS Tunneling Protocol) oder IP-in-IP Tunneln zwischen Knoten übertragen. IP-in-IP-Tunnel werden auch in Unternehmensnetzwerken eingesetzt. Die Überwachung des Verkehrs über Schnittstellen zwischen diesen Knoten ist entscheidend für die Gewährleistung der Dienstleistungsqualität (QoS). Napatech’s Analyse Karten entschlüsseln diese Tunnel und bieten die Möglichkeit, die Lastverteilung auf der Grundlage von Flows innerhalb der Tunnel zu korrelieren und auszugleichen. Analysenanwendungen können diese Fähigkeit nutzen, um mobile Netzwerke und Dienste zu testen, zu sichern und zu optimieren. Um diese verschiedenen Dienstleistungen, die mit jedem Teilnehmer assoziiert sind, effektiv zu analysieren, ist es wichtig diese zu trennen und jeden Einzelnen individuell zu analysieren. Napatech’s Capture Karten haben die Fähigkeit, den Inhalt der Tunnel zu identifizieren, was die Analyse jedes Dienstes ermöglicht, der von einem Teilnehmer verwendet wird. Dies stellt schnell die benötigten Informationen für die Anwendung zur Verfügung und ermöglicht eine effiziente Analyse des Netzwerk- und Anwendungsverkehrs. Dieses Napatech Feature ermöglicht eine Frame-Klassifizierung, Flow-Identifizierung, Filterung, Farbgebung, Slicing und intelligente Multi-CPU-Verteilung womit der Datenverkehr innerhalb des Tunnels ausgewertet werden kann, worum es in den meisten Fällen geht. GTP und IP-in-IP Tunneling sind leistungsstarke Funktionen für Anbieter von Telekommunikationsgeräten, die Produkte zur mobilen Netzwerküberwachung erstellen müssen. Mit dieser Funktion kann Napatech die Datenanalyse vereinfachen und beschleunigen, sodass sich Kunden auf die Optimierung der Anwendung konzentrieren können, um dadurch die Verarbeitungsressourcen von Standard-Servern zu maximieren. |
Handhabung von IP-Fragmentierung
 |
IP-Fragmentierungen treten auf, wenn größere Ethernet-Frames in mehrere Fragmente zerlegt werden müssen, um meist Übertragungen über WAN Strecken zu ermöglichen. Dies kann auf Einschränkungen in bestimmten Teilen des Netzwerks zurückgeführt werden, was typischerweise dann auftritt, wenn GTP-Tunneling-Protokolle verwendet werden. Fragmentierte Frames sind eine Herausforderung für Analyseanwendungen, da alle Fragmente identifiziert und potenziell wieder zusammengefügt werden müssen, bevor die Analyse durchgeführt werden kann. Napatech’s Netzwerkkarten können Fragmente des gleichen Frames identifizieren und sicherstellen, dass diese reassembled und an denselben CPU-Kern für die Verarbeitung gesendet werden. Dies reduziert die Verarbeitungsbelastung für Analyseanwendungen erheblich. |
In-Line Anwendungsunterstützung
|
Die Netzwerkkarten von Napatech unterstützen 20 Gbit/s In-Line-Anwendungen, was den Kunden ermöglicht, leistungsstarke und dennoch flexible In-Line-Lösungen auf Standard-Servern bereitzustellen. Je anspruchsvoller die Anwendung für die CPU ist und je höher die Geschwindigkeit der Links ist, desto größer ist der Nutzen der Napatech Lösung. Die Features umfassen folgendes:
|
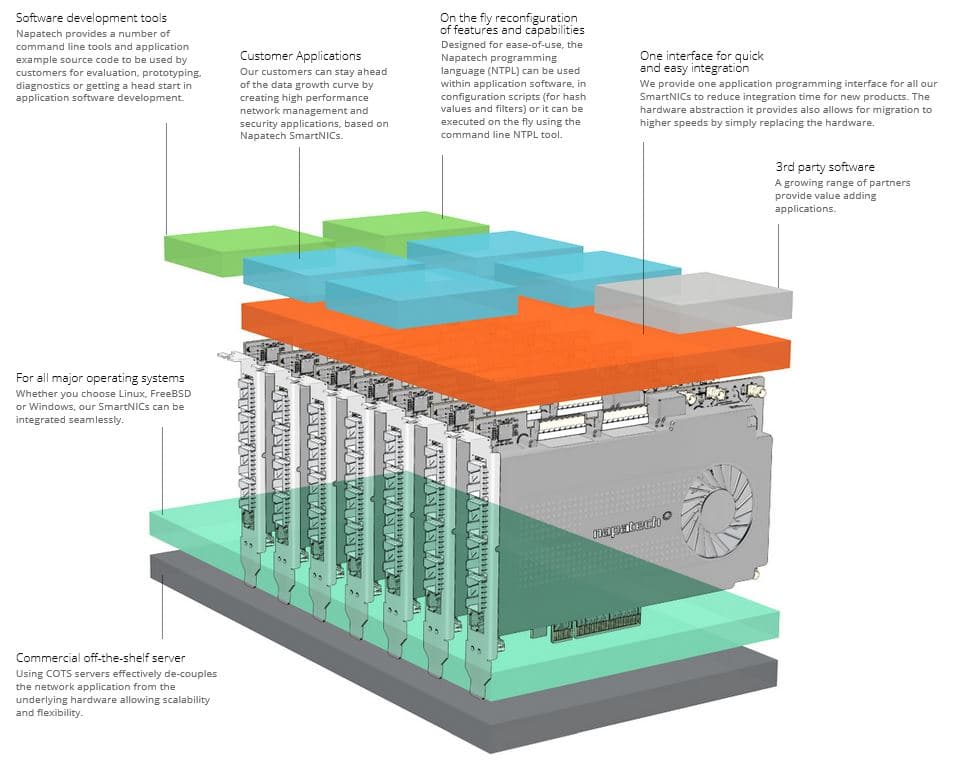
Napatech Software Suite
Die Napatech Software Suite bietet eine übersichtliche Programmierschnittstelle sowie Unterstützung für die bekannte Open-Source-Schnittstelle libpcap und die Windows-Variante WinPcap. Dies ermöglicht den Programmierern eine schnelle Integration von Napatech‘s Analysekarten in ihr System für zuverlässige Netzwerk Monitoring und Sicherheitsanwendungen.
Eine allgemeine API wird für alle Napatech Netzwerkkarten zur Verfügung gestellt, die einen Plug-and-Play Betrieb ermöglicht. Eine intuitive, leicht zu erlernende und dennoch leistungsfähige Programmiersprache bietet ebenfalls eine dynamische und schnelle Konfiguration der Filterung sowie eine intelligente Multi-CPU-Verteilung.


VIDEOS
Suricata performance on Intel PAC vs a NIC
FPGA SmartNICs Providing High Speed Lossless Packet Capture for Trading Analytics
Optimizing Resource Utilization in Edge Data Centers through Virtual Switch Offload
Compact 200G FPGA SmartNIC
DOCUMENTS
Napatech Software Suite

Napatech Produktübersicht

Time Precision Performance

Napatech White Paper

Branchenübergreifende Verwendung
Messung der Netzwerk-Latenz (Finanz)
Unsere Lösungen liefern präzise Daten an Anwendungen, die Netzwerk Latenzen und Paket Laufzeiten sichtbar machen, indem sie alle Transaktionen erfassen und die genaue Zeit jedes Handelsereignisses bis zur Nanosekunde messen. Dadurch können z.B. Finanzinstitute eine optimale Leistung und Transparenz ihrer Handelsinfrastrukturen gewährleisten.
Verwaltung der Netzwerkleistung
Unsere Lösungen stellen Daten an Anwendungen zur Verfügung, die jegliche Netzwerkaktivitäten in Echtzeit überwachen, wodurch eine Analyse der Netzwerk Performance von mehreren Standorten im Netzwerk ermöglicht wird. Dies hilft Netzwerkmanagern, die Effizienz der Infrastruktur zu optimieren.
Fehlerdiagnose und Konformität
Unsere Lösungen liefern Netzwerkdaten an Anwendungen, die einen permanenten Zugriff auf alle Informationen ermöglichen, welche das Netzwerk in der Reihenfolge durchquert haben, in der sie übertragen wurden. Dadurch können Netzwerkmanager grundlegende Vorschriften einhalten und Probleme aus historischen Daten analysieren. Es ermöglicht ihnen auch Maßnahmen zu ergreifen, die verhindern, dass Probleme in der Zukunft erneut auftreten.
Umsatz- und Serviceoptimierung
Unsere Lösungen liefern Daten an Anwendungen, welche das Teilnehmerverhalten sowie eine spezifische App-Nutzung analysieren können, sodass die Betreiber ihre Dienste und Geschäftsmodelle anpassen können, um den Mehrwert zu maximieren.
SMARTNIC MODELLE
| MODEL | NT400D11 | NT200A02 | NT100A01 | NT50B01 | NT40E3 | NT20E3 | NT40A01 |
|---|---|---|---|---|---|---|---|
| PORTS | 2x 100G | 2× 1G/10G, 8x 10G, 2× 10G/25G, 4× 10G/25G, 2x 40G, 2x 100G |
4× 1G/10G, 4× 10G/25G |
2× 1G/10G, 2× 10G/25G |
4x 1G/10G | 2x 1G/10G | 4x 1G |

2x 100G
NT400D11
Das NT400D11 SmartNIC bietet eine vollständige Paketerfassung von Netzwerkdaten mit 200 Gbps ohne Paketverlust.
Die präzise Zeitstempelung im Nanosekundenbereich und die Zusammenführung von Paketen von mehreren Ports gewährleisten das richtige Timing und die richtige Reihenfolge der Pakete.
2x 1G/10G, 8x 10G, 2x 10G/25G,
4x 10G/25G, 2x 40G, 2x 100G
NT200A02
Der NT200A02 SmartNIC basiert auf der leistungsstarken UltraScale+ VU5P FPGA-Architektur von Xilinx und ermöglicht Applikationen mit 2×1/10G, 8x10G, 2×10/25G, 4×10/25G, 2x40G und 2x100G.
Der QSFP28-Formfaktor bietet die Flexibilität, hoch-leistungsfähige Lösungen in 1U-Serverplattformen für bestehende 40G-Netzwerkinfrastrukturen zu schaffen, mit der Freiheit, die Lösung bei Bedarf für 100G-Installationen umzuwidmen. Auch in NEBS-Varianten erhältlich.
4x 1G/10G, 4x 10G/25G
NT100A01
Das NT100A01 SmartNIC basiert auf der leistungsstarken UltraScale+ VU5P FPGA-Architektur von Xilinx und ermöglicht 4×1/10G, 4×10/25G Applikationen.
Auch in NEBS-Varianten erhältlich.
2x 1G/10G, 2x 10G/25G
NT50B01
Der NT50B01 SmartNIC basiert auf der leistungsstarken UltraScale+ VU5P FPGA-Architektur von Xilinx und ermöglicht 2×1/10G-, 2×10/25G-Applikationen.
4x 1G/10G
NT40E3
Das NT40E3 SmartNIC bietet eine vollständige Paketerfassung und -analyse von Ethernet-LANs mit 40 Gbit/s ohne Paketverlust für alle Framegrößen. Intelligente Funktionen beschleunigen die Performance von Applikationen bei extrem niedriger CPU-Last.
Ein dedizierter PPS/PTP Port unterstützt die flexible Zeitsynchronisation. Auch in einer NEBS-Level-3-konformen Variante erhältlich.
2x 1G/10G
NT20E3
Das NT20E3 SmartNIC bietet eine vollständige Paketerfassung und -analyse des Ethernet-LAN bei 20 Gbit/s ohne Paketverlust für alle Framegrößen.
Intelligente Funktionen beschleunigen die Performance von Applikationen bei extrem niedriger CPU-Last.
Ein dedizierter PTP Port unterstützt die flexible Zeitsynchronisation. Auch in einer NEBS-Level-3-konformen Variante erhältlich.
4x 1G
NT40A01
Der NT40A01 SmartNIC bietet eine vollständige Paketerfassung und Analyse von Netzwerkdaten bei 4 Gbit/s ohne Paketverlust.
Die Napatech SmartNIC erfasst alle Frames, einschließlich fehlerhafter Frames, die normalerweise von Standard-NICs verworfen werden. Auch in einer NEBS-Level-3-konformen Variante erhältlich.