Napatech
High-Performance FPGA-based SmartNICs/Network Cards






Built for 100% Packet Capture and Analysis
The Napatech accelerator allows you to merge data from ports into a single, time-ordered analysis stream. It supports 1-128 packet streams using intelligent hardware flow distribution to allow your application to scale to higher packet rates with no packet loss. The Napatech accelerator will distribute packets based on flow or on L3/L4 filter criteria.
PERFECT PERFORMANCEFor any link speed at any time |
COMPLETE PORTFOLIOFrom 1-200G |
PLUG & PLAYOut of the box solution |
SCALE INSIDEMultiple accelerators in one server |
SCALE OUTSIDESynchronize multiple servers |
POWERFULAccelerate your application |
IN-LINEFull throughput with zero packet loss |
MIX SPEEDSMultiple speeds in one server |
BUNDLE APPLICATIONSMore powerful server usage |
Features
Full line-rate packet capture
|
Napatech SmartNICs are highly optimized to capture network traffic at full line-rate, with almost no CPU load on the host server, for all frame sizes. Zero-loss packet capture is critical for applications that need to analyze all the network traffic. If anything needs to be discarded, it is a matter of choice by the application, not a limitation of the SmartNIC. Standard network interface cards (NICs) are not designed for analysis applications where all traffic on a connection or link needs to be analyzed. NICs are designed for communication where data that is not addressed to the sender or receiver is simply discarded. This means that NICs are not designed to have the capacity to handle the amount of data that is regularly transmitted in bursts on Ethernet connections. In these burst situations, all of the bandwidth of a connection is used, requiring the capacity to analyze all Ethernet frames. Napatech SmartNICs are designed specifically for this task and provide the maximum theoretical packet capture capacity. |
Multi-port packet sequence and merge
 |
Napatech SmartNICs typically provide multiple ports. Ports are usually paired, with one port receiving upstream packets and another port receiving downstream packets. Since these two flows going in different directions need to be analyzed as one, packets from both ports must be merged into a single analysis stream. Napatech SmartNICs can sequence and merge packets received on multiple ports in hardware using the precise time stamps of each Ethernet frame. This is highly efficient and offloads a significant and costly task from the analysis application. There is a growing need for analysis appliances that are able to monitor and analyze multiple points in the network, and even provide a network-wide view of what is happening. Not only does this require multiple SmartNICs to be installed in a single appliance, but it also requires that the analysis data from all ports on every accelerator be correlated. With the Napatech Software Suite, it is possible to sequence and merge the analysis data from multiple SmartNICs into a single analysis stream. The merging is based on the nanosecond precision time stamps of each Ethernet frame, allowing a time-ordered merge of individual data streams. |
Intelligent Multi-CPU distribution
 |
Modern servers provide unprecedented processing power with multi-core CPU implementations. This makes standard servers an ideal platform for appliance development. But, to fully harness the processing power of modern servers, it is important that the analysis application is multi-threaded and that the right Ethernet frames are provided to the right CPU core for processing. Not only that, but the frames must be provided at the right time to ensure that analysis can be performed in real time. Napatech Multi-CPU distribution is built and optimized from our extensive knowledge of server architecture, as well as real life experience from our customers. Napatech SmartNICs ensure that identified flows of related Ethernet frames are distributed in an optimal way to the available CPU cores. This ensures that the processing load is balanced across the available processing resources, and that the right frames are being processed by the right CPU cores. With flow distribution to multiple CPU cores, the throughput performance of the analysis application can be increased linearly with the number of cores, up to 128. Not only that, but the performance can also be scaled by faster processing cores. This highly flexible mechanism enables many different ways of designing a solution and provides the ability to optimize for cost and/or performance. Napatech SmartNICs support different distribution schemes that are fully configurable:
|
Hardware Time Stamp
 |
The ability to establish the precise time when frames have been captured is critical to many applications. To achieve this, all Napatech SmartNICs are capable of providing a high-precision time stamp, sampled with 1 nanosecond resolution, for every frame captured and transmitted. At 10 Gbps, an Ethernet frame can be received and transmitted every 67 nanoseconds. At 100 Gbps, this time is reduced to 6.7 nanoseconds. This makes nanosecond-precision time-stamping essential for uniquely identifying when a frame is received. This incredible precision also enables you to sequence and merge frames from multiple ports on multiple SmartNICs into a single, time-ordered analysis stream. In order to work smoothly in the different operating systems supported, Napatech SmartNICs support a range of industry standard time stamp formats, and also offer a choice of resolution to suit different types of applications. 64-bit time stamp formats:
|
Optimum Cache Utilization
 |
Napatech SmartNICs use a buffering strategy that allocates a number of large memory buffers where as many packets as possible are placed back-to-back in each buffer. Using this implementation, only the first access to a packet in the buffer is affected by the access time to external memory. Thanks to cache pre-fetch, the subsequent packets are already in the level 1 cache before the CPU needs them. As hundreds or even thousands of packets can be placed in a buffer, a very high CPU cache performance can be achieved leading to application acceleration. Buffer configuration can have a dramatic effect on the performance of analysis applications. Different applications have different requirements when it comes to latency or processing. It is therefore extremely important that the number and size of buffers can be optimized for the given application. Napatech SmartNICs make this possible. The flexible server buffer structure supported by Napatech SmartNICs can be optimized for different application requirements. For example, applications needing short latency can have frames delivered in small chunks, optionally with a fixed maximum latency. Applications without latency requirements can benefitdata delivered in large chunks, providing more effective server CPU processing by having the data. Applications that need to correlate information distributed across packets can configure larger server buffers (up to 128 GB). Up to 128 buffers can be configured and combined with Napatech multi-CPU distribution (see “Multi-CPU distribution”). |
On-Board Packet Buffering
|
|
Napatech SmartNICs provide on-board memory for buffering of Ethernet frames. Buffering assures guaranteed delivery of data, even when there is congestion in the delivery of data to the application. There are three potential sources of congestion: the PCI interface, the server platform, and the analysis application. PCI interfaces provide a fixed bandwidth for transfer of data from the SmartNIC to the application. This limits the amount of data that can be continuouslytransferred from the network to the application. For example, a 16-lane PCIe Gen3 interface can transfer up to 115 Gbps of data to the application. If the network speed is 2×100 Gbps, a burst of data cannot be transferred over the PCIe Gen3 interface in real time, since the data rate is twice the maximum PCIe bandwidth. In this case, the onboard packet buffering on the Napatech SmartNIC can absorb the burst and ensure that none of the data is lost, allowing the frames to be transferred once the burst has passed. Servers and applications can be configured in such a way that congestion can occur in the server infrastructure or in the application itself. The CPU cores can be busy processing or retrieving data from remote caches and memory locations, which means that new Ethernet frames cannot be transferred from the SmartNIC. In addition, the application can be configured with only one or a few processing threads, which can result in the application being overloaded, meaning that new Ethernet frames cannot be transferred. With onboard packet buffering, the Ethernet frames can be delayed until the server or the application is ready to accept them. This ensures that no Ethernet frames are lost and that all the data is made available for analysis when needed. |

Tunneling Support
 |
In mobile networks, all subscriber Internet traffic is carried in GTP (GPRS Tunneling Protocol) or IP-in-IP tunnels between nodes in the mobile core. IP-in-IP tunnels are also used in enterprise networks. Monitoring traffic over interfaces between these nodes is crucial for assuring Quality of Service (QoS). Napatech SmartNICs decode these tunnels, providing the ability to correlate and load balance based on flows inside the tunnels. Analysis applications can use this capability to test, secure, and optimize mobile networks and services. To effectively analyze the multiple services associated with each subscriber, it is important to separate them and analyze each one individually. Napatech SmartNICs have the capability to identify the contents of tunnels, allowing for analysis of each service used by a subscriber. This quickly provides the neededinformation to the application, and allows for efficient analysis of network and application traffic. The Napatech features for frame classification, flow identification, filtering, coloring, slicing, and intelligent multi-CPU distribution can thus be applied to the contents of the tunnel rather than the tunnel itself, leading to a more balanced processing and a more efficient analysis. GTP and IP-in-IP tunneling are powerful features for telecom equipment vendors who need to build mobile network monitoring products. With this feature, Napatech can off-load and accelerate data analysis, allowing customers to focus on optimizing the application, and thereby maximizing the processing resources in standard servers. |
IP fragment handling
 |
IP fragmentation occurs when larger Ethernet frames need to be broken into several fragments in order to be transmitted across the network. This can be due to limitations in certain parts of the network, typically when GTP tunneling protocols are used. Fragmented frames are a challenge for analysis applications, as all fragments must be identified and potentially reassembled before analysis can be performed. Napatech SmartNICs can identify fragments of the same frame and ensure that these are associated and sent to the same CPU core for processing. This significantly reduces the processing burden for analysis applications. |
In-line application support
|
The Napatech SmartNIC family supports 4 Gbps in-line applications enabling customers to create powerful, yet flexible in-line solutions on standard servers. The more CPU-demanding the application is, and the higher the speeds of links, the higher the value of this solution. Features include:
|
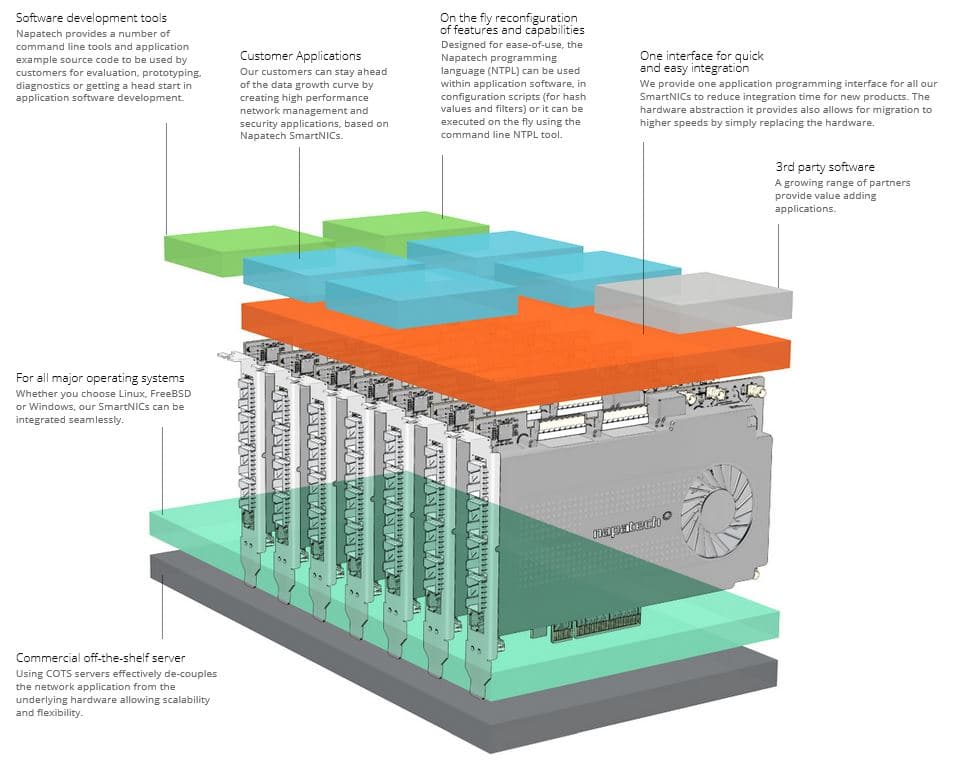
Napatech Software Suite
Napatech Software Suite provides a well-defined application programming interface as well as support for the well-known, open-source interface libpcap and the Windows variant called WinPcap. This allows programmers to quickly integrate Napatech SmartNICs for network monitoring and security applications into their system.


VIDEOS
Compact 200G FPGA SmartNIC
DOCUMENTS
Napatech Software Suite

Napatech Product Overview

Napatech Time Precision Performance

Napatech Functional Overview

Napatech White Paper

The Ultimate Performance Combination of
FPGA Software and Hardware for Capture, Inline and Virtualization
is ideal for performing high-speed packet capture with nanosecond timestamping and replay with precise inter-frame gap control.
boosts applications by offloading packet and flow processing, providing unmatched visibility and performance.
offloads and accelerates the Open vSwitch (OVS) dataplane to enhance CPU efficiency, scalability and network performance.
enables end users and OEMs to deploy their own FPGA IP on Napatech’s industry-proven SmartNIC platform.
Used across industries
Financial latency measurement
Our solutions deliver data to applications that make delays visible by capturing all transactions and measuring the exact time of each trading event up to the nanosecond. This enables financial institutions to guarantee optimal performance and transparency of their trading infrastructure.
Network performance management
Our solutions deliver data to applications that monitor and troubleshoot all network activity in real time, enabling analysis of network performance metrics from multiple locations in the network. This helps network managers to optimize infrastructure efficiency.
Troubleshooting and compliance
Our solutions deliver data to applications that provide access to all information that has passed through the network in the order it was received. This allows network managers to comply with regulations, as well as analyze problems from historical data. It also allows them to take actions that will prevent problems from recurring in the future.
Revenue and services optimization
Our solutions deliver data to applications that can analyze subscriber behavior as well as specific app usage, enabling operators to adjust their services and business models to maximize value.
SMARTNIC MODELS
| MODEL | NT400D11 | NT200A02 | NT100A01 | NT50B01 | NT40E3 | NT20E3 | NT40A01 |
|---|---|---|---|---|---|---|---|
| PORTS | 2x 100G | 2× 1G/10G, 8x 10G, 2× 10G/25G, 4× 10G/25G, 2x 40G, 2x 100G |
4× 1G/10G, 4× 10G/25G |
2× 1G/10G, 2× 10G/25G |
4x 1G/10G | 2x 1G/10G | 4x 1G |

2x 100G
NT400D11
The NT400D11 SmartNIC provides full packet capture of network data at 200 Gbps with zero packet loss.
Nanosecond precision time-stamping and merge of packets from multiple ports ensures correct timing and sequencing of packets.
2x 1G/10G, 8x 10G, 2x 10G/25G,
4x 10G/25G, 2x 40G, 2x 100G
NT200A02
The NT200A02 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 2×1/10G, 8x10G, 2×10/25G, 4×10/25G, 2x40G, 2x100G applications. The QSFP28 form factor offers flexibility to create high-performance solutions in 1U server platforms for existing 40G network infrastructures, with the freedom to repurpose the solution for 100G installations when necessary. Also available in NEBS variants.
4x 1G/10G, 4x 10G/25G
NT100A01
The NT100A01 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 4×1/10G, 4×10/25G applications. Also available in NEBS variants.
2x 1G/10G, 2x 10G/25G
NT50B01
The NT50B01 SmartNIC is based on Xilinx’s powerful UltraScale+ VU5P FPGA architecture and enables 2×1/10G, 2×10/25G applications.
4x 1G/10G
NT40E3
The NT40E3 SmartNIC provides full packet capture and analysis of Ethernet LAN at 40 Gbps with zero packet loss for all frame sizes. Intelligent features accelerate application performance with extremely low CPU load. Flexible time synchronization support is included with a dedicated PPS/PTP port. Also available in a NEBS level 3 compliant variant.
2x 1G/10G
NT20E3
The NT20E3 SmartNIC provides full packet capture and analysis of Ethernet LAN at 20 Gbps with zero packet loss for all frame sizes. Intelligent features accelerate application performance with extremely low CPU load. Flexible time synchronization support is included with a dedicated PTP port. Also available in a NEBS level 3 compliant variant.
4x 1G
NT40A01
The NT40A01 SmartNIC provide full packet capture and analysis of network data at 4 Gbps with zero packet loss. The Napatech SmartNIC will capture all frames, including erroneous frames normally discarded by standard NICs. Also available in a NEBS level 3 compliant variant.