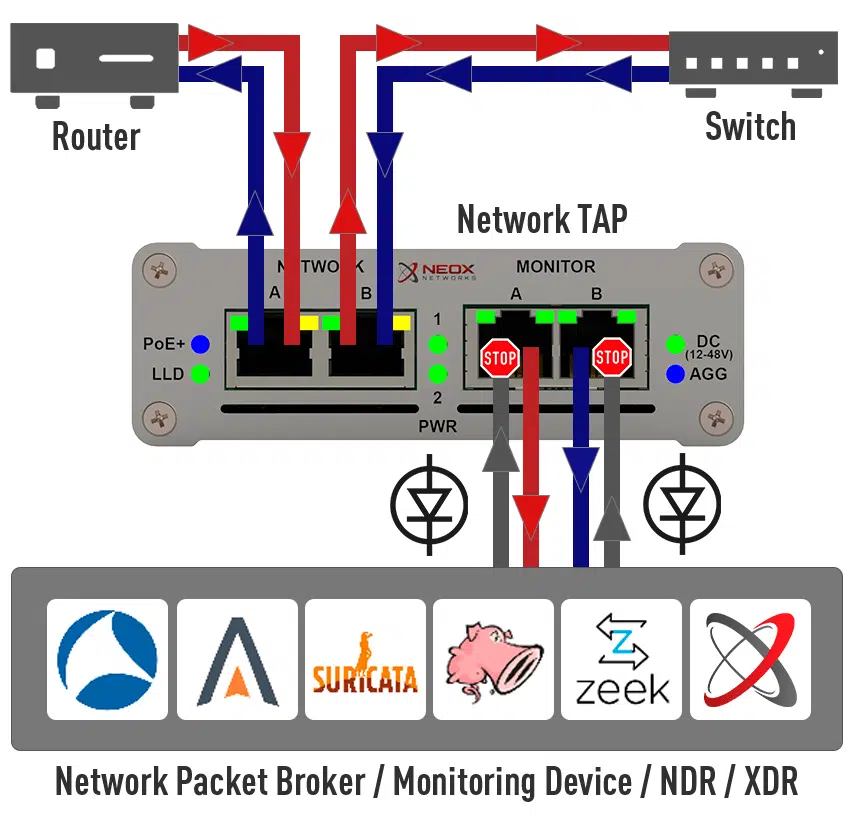
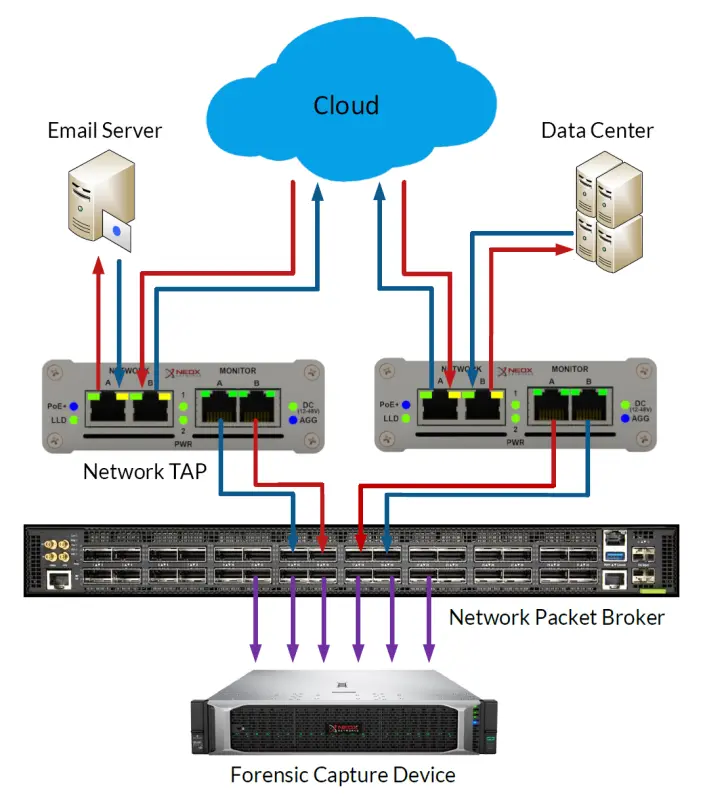
In today’s cyber threat landscape, incident response (IR) and digital forensics are non-negotiable for any organization. But what if I told you there’s a way to supercharge your IR and forensics capabilities? Enter network observability.
What's the Big Deal with
Incident Response & Forensics?
- Incident Response (IR)
- Swift Containment: IR is about minimizing damage. The faster you identify and isolate an incident, the less it can spread.
- Damage Control: Effective IR helps you restore systems, mitigate losses, and get back to business as usual ASAP.
- Learning from Mistakes: Analyzing incidents helps you strengthen your security posture and prevent future breaches.
- Digital Forensics
- Understanding the “Who” and “How”: Forensics digs deep into the evidence to identify the attacker, their tactics, and the extent of the compromise.
- Legal and Regulatory Compliance: Detailed forensic reports may be required for investigations, litigation, or to meet compliance standards.
The Observability Advantage:
Shining a Light on the Network
Network observability is the ability to comprehensively understand the health, performance, and security of your network in real-time. Here’s how it elevates your IR and forensics game:

- Early Detection: Observability tools provide granular visibility into network traffic, anomalies, and potential indicators of compromise (IOCs). This enables proactive detection and response, often before an attacker can cause significant damage.
- Faster Triage: When an incident occurs, observability data acts as a “fast-forward” button. You can quickly pinpoint the source of the attack, affected systems, and the attacker’s movements. This accelerates the triage process, allowing for targeted containment.
- Precise Forensics: Network observability provides a treasure trove of forensic evidence. You can track the attacker’s every step, the commands they used, and the data they exfiltrated. This level of detail is invaluable for investigations and legal proceedings.
- Data Correlation: By integrating network observability data with other security tools (like SIEMs and EDRs), you gain a holistic view of the incident. This correlation helps you uncover patterns, identify root causes, and refine your security strategies.
Why are the tools secret weapons?
Network TAPs (Test Access Points) and Full Packet Capture (FPC) form the cornerstone of network observability. TAPs provide a non-intrusive, reliable way to access raw network traffic, ensuring no packet is missed or altered. This comprehensive visibility, combined with FPC’s ability to store every packet for later analysis, enables deep insights into network behavior, performance bottlenecks, and security threats.
Network Analysis tools can then dissect this rich data, providing a granular view of applications, protocols, and user activities. This combination unlocks the ability to troubleshoot complex issues, identify anomalies in real-time, and proactively mitigate security risks, making it an indispensable arsenal in the pursuit of comprehensive network observability.
Full Packet Capture (FPC) and Network Analysis are a secret weapon for CISOs due to several key reasons:
- Unparalleled Visibility: FPC captures and stores every bit of network traffic, providing an unfiltered view of all activity. This level of visibility is unmatched by traditional monitoring tools, which often rely on sampled data or summaries. This allows CISOs to:
- Detect Stealthy Threats: FPC can uncover hidden or obfuscated threats that may evade traditional security tools.
- Investigate Incidents Thoroughly: FPC provides the raw data needed for in-depth forensic analysis, enabling CISOs to understand the root cause, impact, and scope of security incidents.
- Retrospective Analysis: FPC acts like a DVR for your network. CISOs can rewind and replay traffic to analyze past events, even if they were not initially identified as suspicious. This is invaluable for:
- Threat Hunting: Proactively searching for indicators of compromise (IOCs) that may have been missed.
- Compliance Audits: Demonstrating adherence to regulatory requirements by providing detailed records of network activity.
- Contextual Awareness: Network Analysis tools extract meaningful insights from the raw FPC data. By correlating events, identifying patterns, and applying advanced analytics, CISOs can:
- Understand Network Behavior: Gain a deep understanding of normal traffic patterns, making it easier to detect anomalies and potential threats.
- Prioritize Risks: Focus on the most critical threats by identifying the most vulnerable systems, users, and applications.
- Optimize Security Controls: Fine-tune security policies and configurations based on real-world data.
- Proactive Defense: The combination of FPC and Network Analysis allows CISOs to move from a reactive to a proactive security posture. By identifying and mitigating threats early in the attack lifecycle, they can:
- Prevent Data Breaches: Detect and stop attacks before they can cause significant damage or data loss.
- Reduce Downtime: Minimize the impact of security incidents on business operations.
- Strengthen Resilience: Build a more robust and resilient security infrastructure.
- Regulatory Compliance: In many industries, regulatory frameworks mandate the ability to monitor and log network traffic. FPC and Network Analysis provide the necessary capabilities to meet these requirements, demonstrate due diligence, and avoid costly penalties.
Real-World Impact: Case Study
Imagine a ransomware attack. With network observability, you could quickly:
- Detect the initial infection vector (e.g., a phishing email, a vulnerable server).
- Trace the ransomware’s lateral movement across your network.
- Identify the command-and-control (C2) servers used by the attacker.
- Gather detailed logs of the encryption process.
Armed with this information, you can isolate the affected systems, disrupt the attacker’s communication, and potentially recover encrypted files. The forensic data will be crucial for legal action and improving your security posture.

Key Takeaways
- Network observability is a force multiplier for incident response and forensics.
- It enables early detection, faster triage, precise forensic analysis, and improved threat intelligence.
- Implementing network observability is a strategic investment in your organization’s security and resilience.
- Full Packet Capture and Network Analysis provide CISOs with a powerful combination of visibility, context, and proactive defense. By leveraging these tools, CISOs can gain a deep understanding of their network’s security posture, detect and respond to threats more effectively, and ultimately safeguard their organization’s most valuable assets.