In my current article, I would like to discuss the topic of network access using Network TAP and show you the advantages of this technology.
Nowadays, networks are the core element for the transport of communication data and the exchange of electronic information. The number of network-enabled products is increasing rapidly and the medium of the Internet has long since become an integral part of our lives. In the home sector, too, manufacturers are relying more and more on network-capable elements, thus enabling users to have convenient access (to such devices) regardless of their location.
Life without the internet is hardly imaginable and today’s computer networks are very important.
But what happens if the network fails
or is not available in the usual way?

The impact of a network failure can have huge financial consequences and may well cause worldwide chaos. With a proactive monitoring system, you can continuously monitor your IT service quality and thus significantly minimise the risk of a failure. Permanent monitoring of your IT infrastructure also helps you with investment decisions, as you can obtain detailed analyses and evaluations from the information obtained and thus derive trends. Especially when it comes to capacity planning or ensuring QoS (Quality of Service), comprehensive monitoring is indispensable.
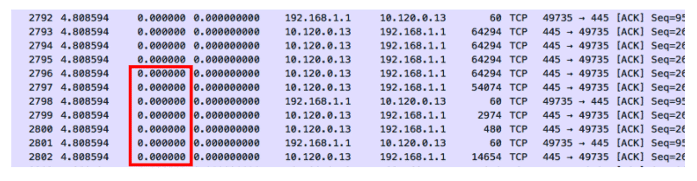
A network monitoring system is not an off-the-shelf product and this article is about network monitoring using the so-called “packet capture” method. With this method, all network data to be analysed is evaluated byte by byte. The transmitted digital information is recorded by means of capturing and analysed by the monitoring tool.
But where does this data come from and how reliable are these sources of information?
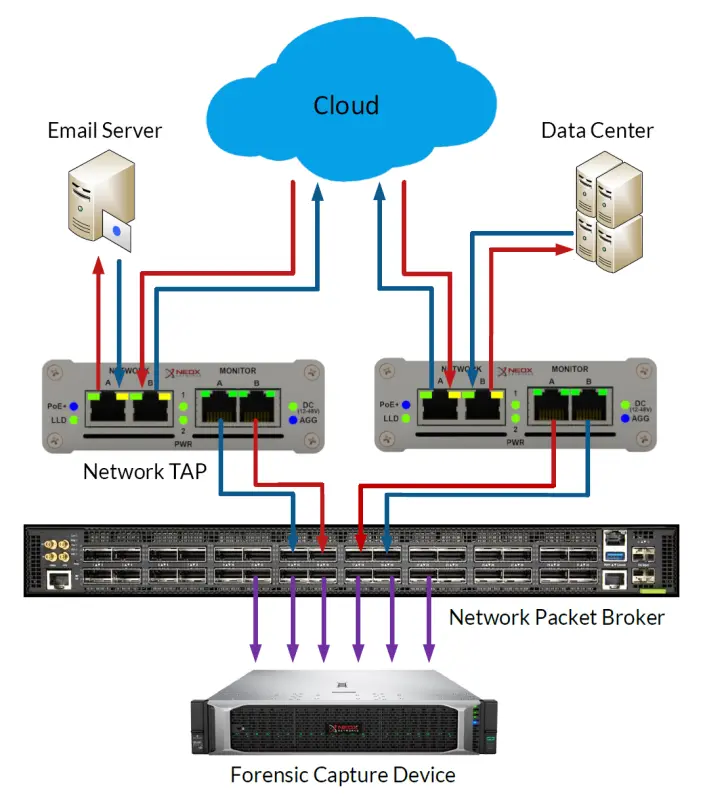
Network Taps are best suited for this measurement technique. What are these devices and how are they used? Network Taps usually have four physical ports and are transparently looped into the network line to be analysed. The information transmitted on the network ports is mirrored on the monitoring interfaces.
This technique provides a 100% insight into the network events and allows the data to be analysed without affecting the network performance. Since every single transmitted network packet is copied out of the line, one would also be able to create a “backup” of one’s network data with this method.
Technical advantages of Network TAPs:
- Network Taps do not impair the function of the active network line at all
- 100% transparent and invisible to hackers and other attackers
- Network Taps are passive and behave like a cable bridge (fail-closed) in case of failure
- Completely transmits the network data
- The integrity of the data is guaranteed
- 100% reaction-free due to galvanic isolation (Data Diode Function)
- Network packets with CRC errors are also routed out
- Non-compliant data according to IEEE 802.3 are copied out
- Works protocol-independent and supports jumbo frames
- Classic network taps forward the data in full-duplex mode
- Overbooking of output ports excluded
- No tedious configuration required, once installed it delivers the desired data
- Errors due to incorrect packet order excluded
- Configuration errors excluded, as commissioning is done by Plug’n Play
- Media-converting Network Taps available for the widest possible range of applications
If you have performance problems in the network or already have a failure, fast action is usually called for. In such situations, you have little time to configure SPAN ports and want to start troubleshooting immediately. But what if there is no SPAN port available at the time or the password to the switch is not at hand? But it can also be much worse, namely that the switch is busy due to a DDoS attack or a bandwidth-intensive application, making analysis on the SPAN port virtually impossible.
It could also happen that the switch is not available in the usual way due to a malicious attack. Especially for security reasons or to detect industrial espionage, network taps are indispensable, as they emit data at the physical level, regardless of what is happening in the network, and thus always allow reliable network analysis and monitoring.
Application examples of Network TAPs:
- Proactive Network Monitoring
- Capacity Planning Fiber Network TAP
- Base Lining (Trend Analysis)
- Security and Forensics
- Network analysis and troubleshooting
- Network and Application Performance Analysis
- Lawful Interception (legally compliant monitoring)
- SLA monitoring
- Compliance monitoring
- Database monitoring
Conclusion
There are many reasons to use Network TAPs and we hope that we have been able to give you an overview of the benefits in this article.