Laut IBM X-Force hat sich die Emotet-Malware in letzter Zeit in Deutschland und Japan verbreitet und zielt immer aggressiver auf Unternehmen in dieser Region ab.
Emotet ist ein Banking-Trojaner, der sich über makrofähige E-Mail-Anhänge verbreitet, die Links zu bösartigen Websites enthalten. Er funktioniert in erster Linie als Downloader für andere Malware, nämlich den TrickBot-Trojaner und die Ryuk-Ransomware.
Aufgrund seines polymorphen Charakters kann er traditionelle signaturbasierte Erkennungsmethoden umgehen, was seine Bekämpfung besonders schwierig macht.
Sobald die Malware in ein System eingedrungen ist, infiziert sie laufende Prozesse und stellt eine Verbindung zu einem entfernten C&C-Server her, um Anweisungen zu erhalten, Downloads auszuführen und gestohlene Daten hochzuladen (us-cert.gov).
Traditionell hat Emotet die Rechnungsbenachrichtigungen von Unternehmen zur Tarnung verwendet und dabei oft das Branding seriöser Institutionen nachgeahmt, um sich selbst als legitim darzustellen. Diese Strategie ermöglichte es der Malware, Opfer in den USA (52 % aller Angriffe), Japan (22 %) und Ländern der EU (japan.zdnet.com) ins Visier zu nehmen. Ein Vorfall im Dezember 2019 veranlasste die Stadt Frankfurt, Sitz der Europäischen Zentralbank, ihr Netzwerk zu schließen (zdnet.com).
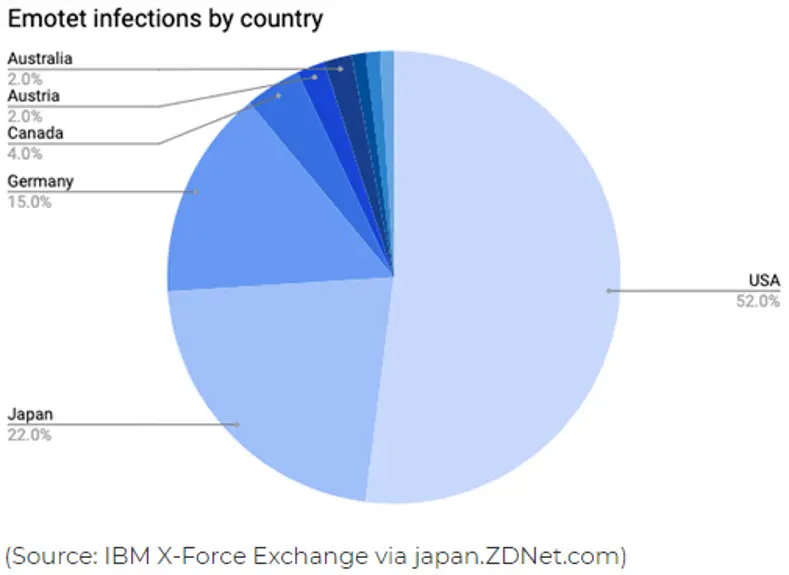
In Japan allerdings agiert die Malware im Vergleich zu den vergangenen Jahren mit viel größerer Aggressivität. Ende 2019 wurde eine erhöhte Aktivität gemeldet, und kürzlich, nach dem Ausbruch des Coronavirus in China, änderte Emotet seine Taktik und verbreitet sich nun in ganz Japan in Form von gefälschten Gesundheitswarnungen mit beunruhigenden Berichten über Coronavirus-Fälle in den Präfekturen Gifu, Osaka und Tottori (IBM X-Force Exchange).
Dies ist ein gutes Beispiel dafür, was diese Art von Malware so gefährlich macht – sie ist nicht nur resistent gegen die Erkennung durch signaturbasierte Methoden, sondern manipuliert auch grundlegende menschliche Emotionen, um sich selbst zu verbreiten.
Der Schutz vor Emotet erfordert daher komplexere Maßnahmen. Neben einer gut informierten Prävention besteht ein wirksamer Weg, damit umzugehen, darin, sich auf eine Verhaltensanalyse zu verlassen, die nach Indikatoren für Kompromisse (IoC) sucht.
Im Fall von Flowmon nimmt dies die Form des InformationStealers Verhaltensmusters (BPattern) an, das als Standard-Erkennungsmethode in Flowmon ADS existiert und die Symptome der Präsenz von Emotet im Netzwerk beschreibt.
BPatterns kann man sich als eine Art Beschreibung dessen vorstellen, wie sich verschiedene bösartige Akteure im Netzwerk manifestieren. Sie ermöglichen es dem System, Bedrohungen durch andere Aktivitäten zu erkennen, während es den Datenverkehr überwacht und kritisch bewertet.
Im Gegensatz zu traditionellen Signaturen suchen BPatterns nicht nach einem bestimmten Stück Code und behalten so ihre Fähigkeit, Bedrohungen zu erkennen, auch wenn sie sich verändern und sich im Laufe ihres Lebenszyklus weiterentwickeln.

Laut einer von Fortinet veröffentlichten Analyse verwendet Emotet 5 URLs zum Herunterladen von Nutzlast und 61 fest kodierte C&C-Server (fortinet.com/blog).
Diese Informationen sind im BPattern enthalten und werden vom System verwendet, um die Infektion zu erkennen und einzudämmen, bevor sie sich ausbreiten kann. Für eine zusätzliche Schutzebene gibt es auch ein BPattern für TrickBot (TOR_Malware). Beide Muster werden regelmäßig aktualisiert, je nachdem, wie sich die Trojaner entwickeln, und werden den Benutzern im Rahmen regelmäßiger Updates zur Verfügung gestellt.
Es war Flowmons Partner Orizon Systems, der uns auf die erhöhte Inzidenz der Emotet-Malware aufmerksam machte und die jüngste Aktualisierung veranlasste.
Aber kein Schutz ist unfehlbar, und jedem wird empfohlen, mehrere Ebenen des Cyber-Schutzes an Ort und Stelle und auf dem neuesten Stand zu halten – einschließlich Antivirus, IoC-Erkennung auf Firewalls, Intrusion Detection Systems (IDS) und Verhaltensanalyse im Netzwerk.
Da sich Emotet durch gefälschte E-Mails verbreitet, sollten Benutzer beim Öffnen von Anhängen Vorsicht walten lassen, insbesondere diejenigen, die täglich mit Rechnungen und Dokumenten von Dritten in Kontakt kommen, und verdächtige oder ungewöhnliche E-Mails an das Sicherheitsteam melden.
Um mehr über die Erkennung von Bedrohungen mit Flowmon ADS zu erfahren, kontaktieren Sie uns für weitere Informationen oder probieren Sie eine Demo aus.