In diesem konkreten Testfall haben wir einen Xena VulcanBay mit 2x 40 Gbps QSFP+ Interfaces verwendet, um einige Next-Generation Firewalls bezüglich ihrer Performance zu testen. Konkret waren wir an folgenden Testszenarien interessiert:
- Reiner Durchsatz (Throughput)
- Hohe Anzahl von Verbindungen (Session Load)
- Einsatz von NAT
- Realistischer Traffic
- Längere Testzeiträume, währenddessen wir neue Firewallregeln „gepusht“ haben, um potentielle Einbrüche im Durchsatz feststellen zu können
In diesem Beitrag wollen wir zeigen, wie wir den Xena VulcanBay inkl. dessen Management, dem VulcanManager, sowie einen Cisco Nexus Switch zum Verbinden der Firewall-Cluster eingesetzt haben. Wir listen unsere Testszenarien auf und geben ein paar Hinweise zu potentiellen Stolpersteinen.
Für unsere Tests hatten wir einen Xena VulcanBay Vul-28PE-40G mit Firmware Version 3.6.0, Lizenzen für die beiden 40 G Interfaces sowie die vollen 28 Packet Engines zur Verfügung. Der VulcanManager lief auf Version 2.1.23.0. Da wir nur einen einzelnen VulcanBay (und nicht mehrere an verteilten Standorten) verwendet haben, konnte der einzige Admin-User die vollen 28 Packet Engines auf diese beiden Ports gleichermaßen verteilen.
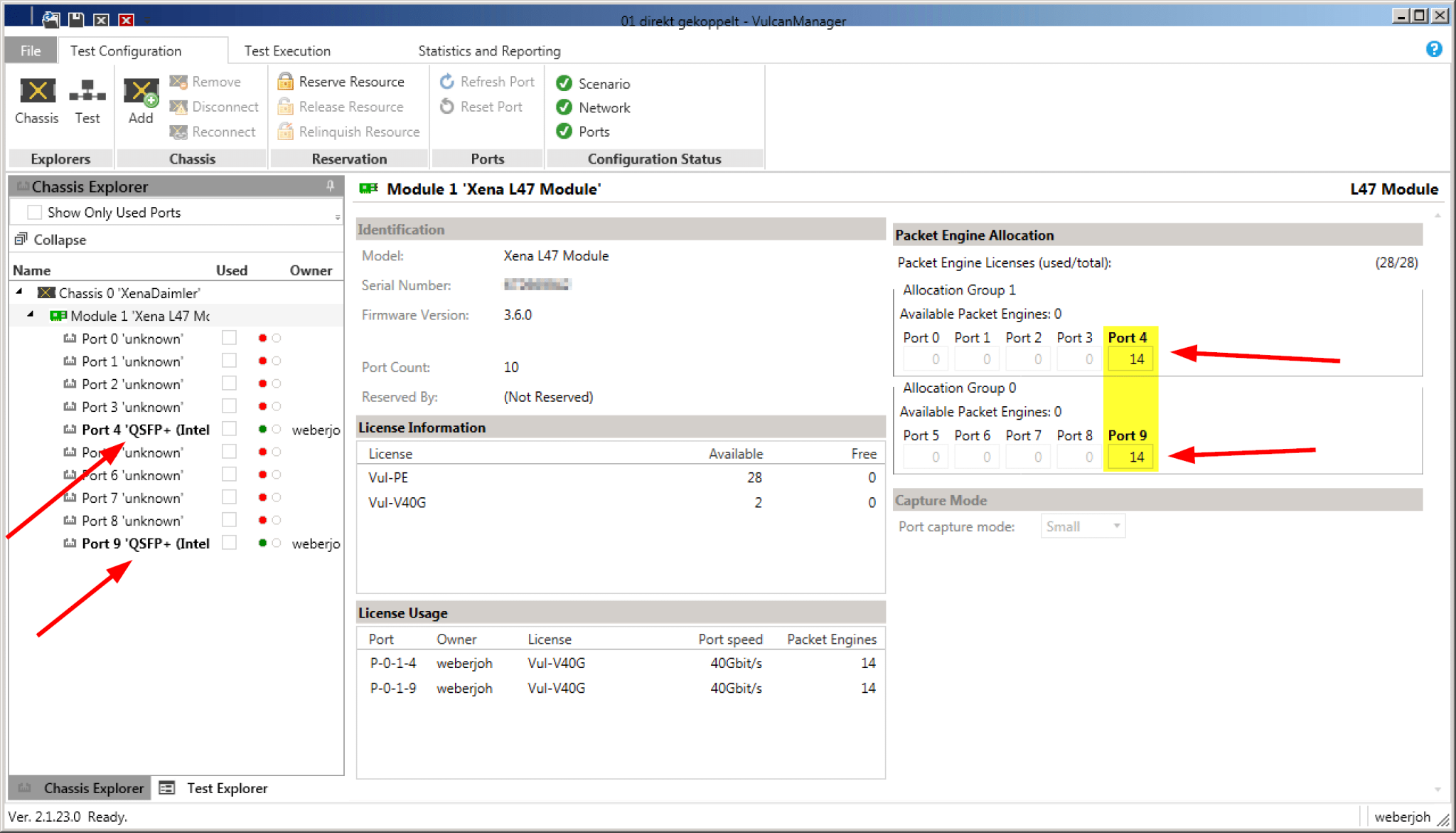
Für Tests mit bis zu 80 G Durchsatz reichten zwei QSFP+ Module (links) sowie die Verteilung der Packet Engines auf eben diese Ports (rechts).
Für den Anschluss des VulcanBays an die jeweiligen Firewall-Cluster haben wir einen einzelnen Cisco Nexus Switch mit genügend QSFP+ Modulen und entsprechendem Durchsatz verwendet. Da wir alle Firewall-Cluster als auch den VulcanBay gleichzeitig an diesen Switch angeschlossen hatten, und für die Tests stets die gleichen IPv4/IPv6 Adressbereiche genommen hatten, konnten wir rein mit dem „shutdown / no shutdown“ einzelner Interfaces darüber entscheiden, welchen Firewallhersteller wir nun testen wollten. Somit war das komplette Labor aus der Ferne steuerbar. Sehr praktisch für den typischen Fall eines Homeoffice Mitarbeiters. Außerdem war es so einfach möglich, den VulcanBay auch „mit sich selbst“ zu verbinden, um aussagekräftige Referenzwerte aller Tests zu bekommen. Hierfür wurden temporär beide 40 G Interface zum VulcanBay in das gleiche VLAN konfiguriert.
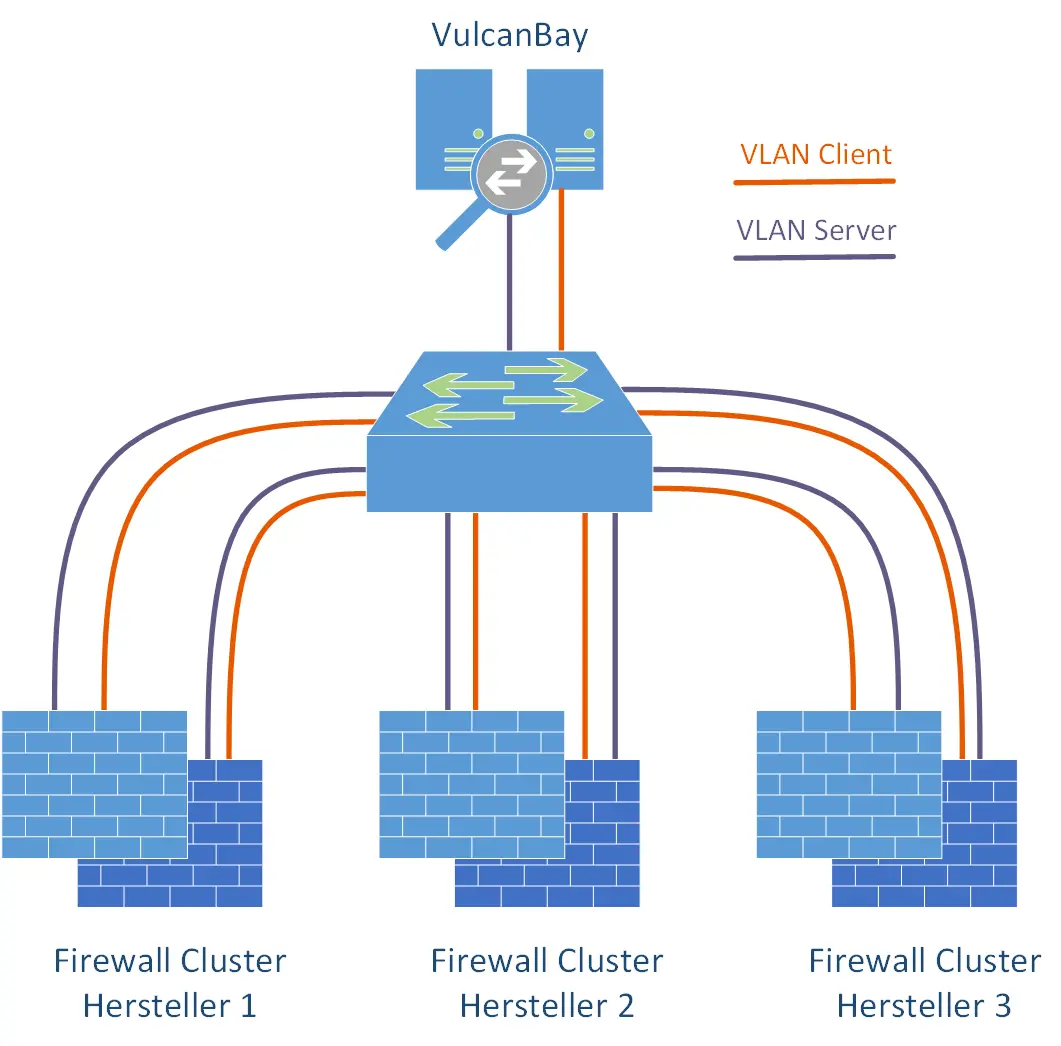
Mit jeweils zwei Leitungen für Client und Server wurden alle Firewall Cluster an einen zentralen Switch gekoppelt. Ebenso der VulcanBay von Neox Networks.
In unserem Fall wollten wir verschiedene Firewalls im Layer 3 Modus testen. Um dieses „Device Under Test“ (DUT) routingtechnisch einzubinden haben wir entsprechende Subnetze angelegt – sowohl für das veraltete IPv4 Protokoll als auch für IPv6. Die vom VulcanBay simulierten IP Subnetze liegen nachher an der Firewall direkt an. Im Falle eines /16er IPv4 Netztes muss also genau dieses /16 Netz auch an der Firewall konfiguriert werden. Wichtig ist vor allem der Default Gateway, beispielsweise 10.0.0..1 für das Client IPv4 Netz. Verwendet man zusätzlich die Option „Use ARP“ (rechte Seite), muss man sich um die eingeblendeten MAC Adressen nicht kümmern. Der VulcanBay löst diese selbst auf.
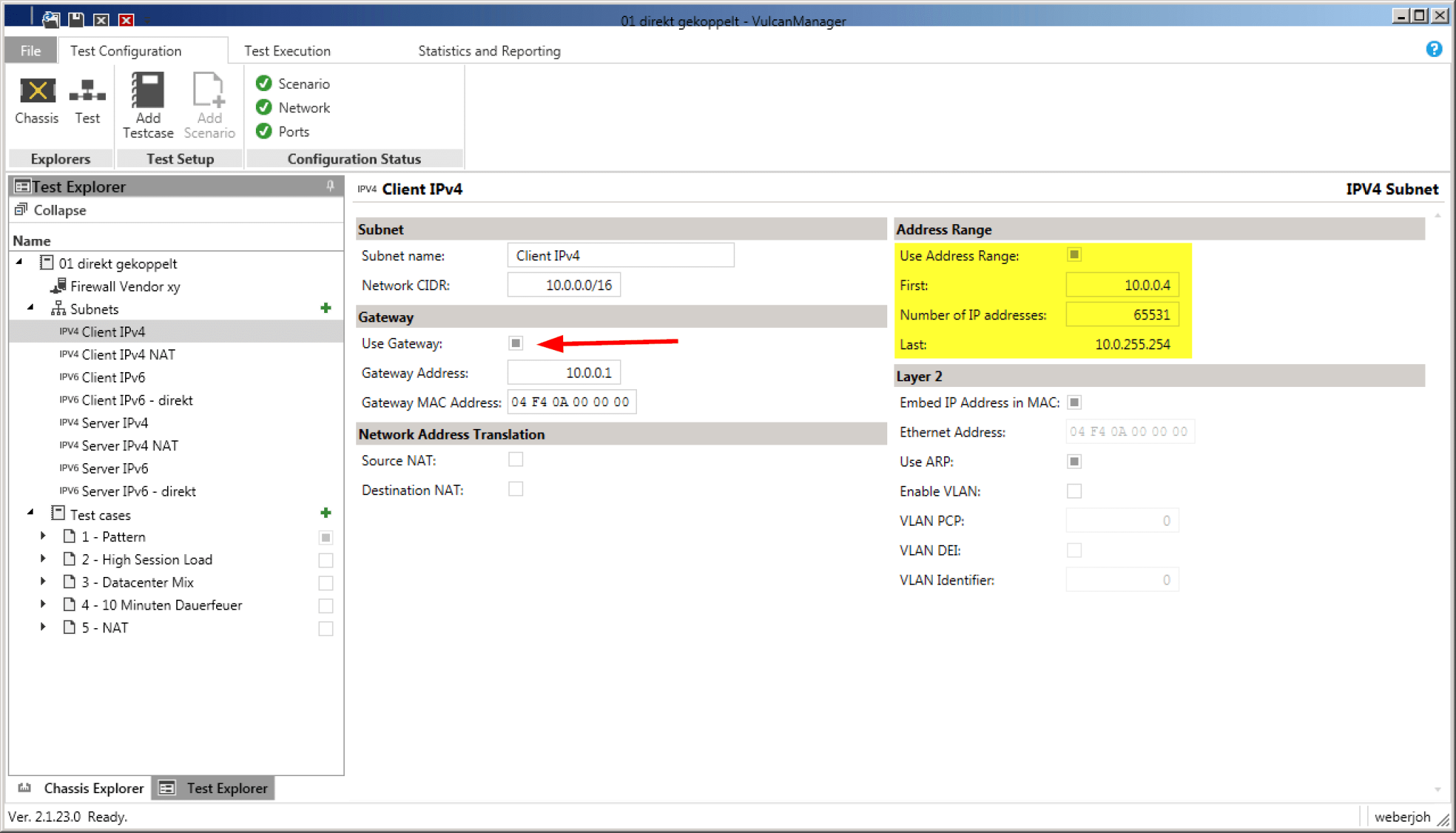
Der Adressbereich muss zwingend angepasst werden, damit die durchgeführten Tests nicht einem MAC Flooding gleichkommen.
Bei IPv6 verhält es sich gleichermaßen. Hier wird das Netzwerk nicht in der sonst üblichen Slash-Notation eingegeben, sondern einfach nur der Gateway und der Address Range bestimmt. Per „Use NDP“ löst auch hier der VulcanBay die Layer 2 MAC-Adresse zur Layer 3 IPv6-Adresse selbstständig auf.

Per „Use Gateway“ teil man dem VulcanBay mit, dass ein dazwischenliegender Router/Firewall für die Tests verwendet werden soll.
1) Reiner Durchsatz (Throughput): In dem ersten Testszenario ging es uns rein um den Durchsatz der Firewalls. Hierfür haben wir das Szenario „Pattern“ gewählt, einmal für IPv4 und einmal für IPv6, was automatisch die Ratio auf 50-50 legt. In den Einstellungen haben wir zusätzlich „Bidirectional“ ausgewählt um in beiden Fällen Daten in beide Richtungen, also Duplex, durchzuschieben. So konnten wir mit den 2x 40 G Interfaces den maximalen Durchsatz von vollen 80 G erreichen. Um die Bandbreite über mehrere Sessions zu verteilen (was im echten Leben der realistischere Testfall ist), wählten wir 1000 User aus, welche jeweils von 100 Source Ports zu 10 Servern Verbindungen aufbauen sollten. Macht für IPv4 und IPv6 jeweils 1 Million Sessions. Bei einer Ramp-Up Time von 5 Sekunden, also einem sanften Anstieg der Verbindungen anstelle der sofortigen vollen Last, lief der reine Test danach 120 Sekunden durch, bevor er ebenfalls eine Ramp-Down Time von 5 Sekunden hatte.
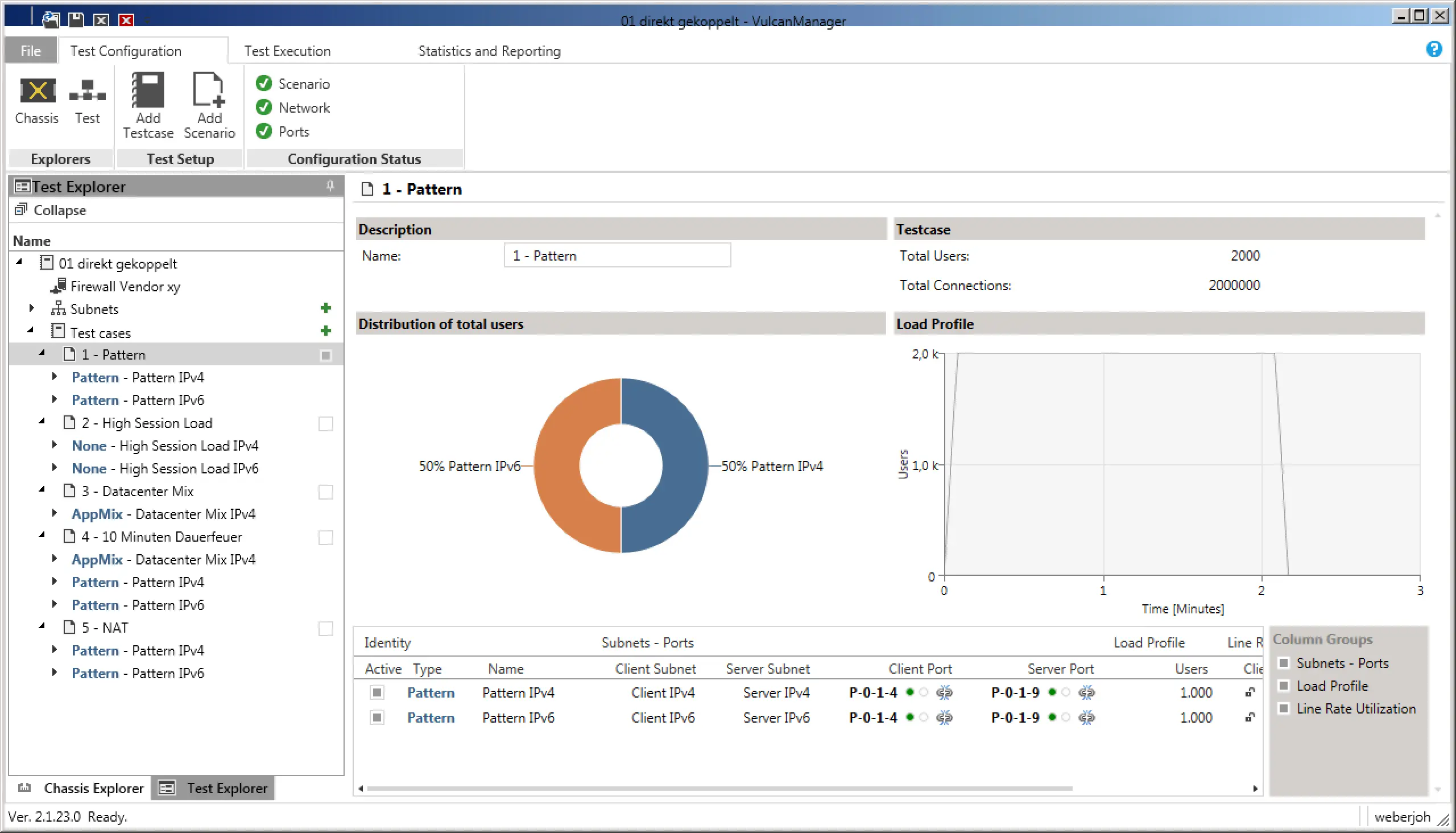
Testszenario „Pattern“ mit einer 50-50 Verteilung von IPv4 und IPv6. Das „Load Profile“ (rechts) zeigt die zu simulierenden User anhand der Zeitachse.
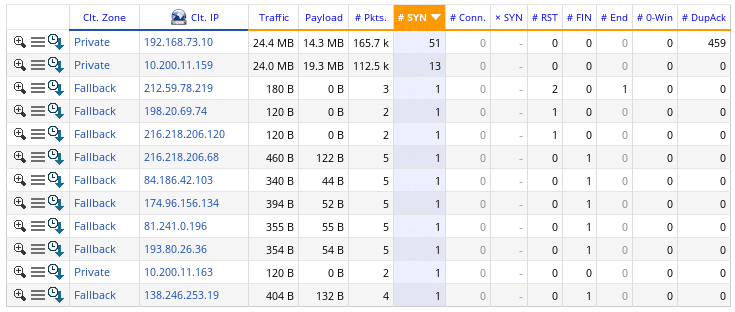
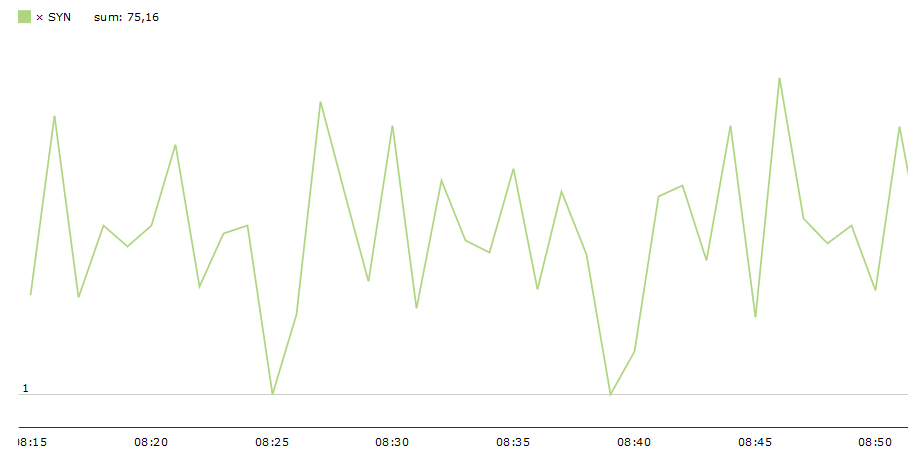
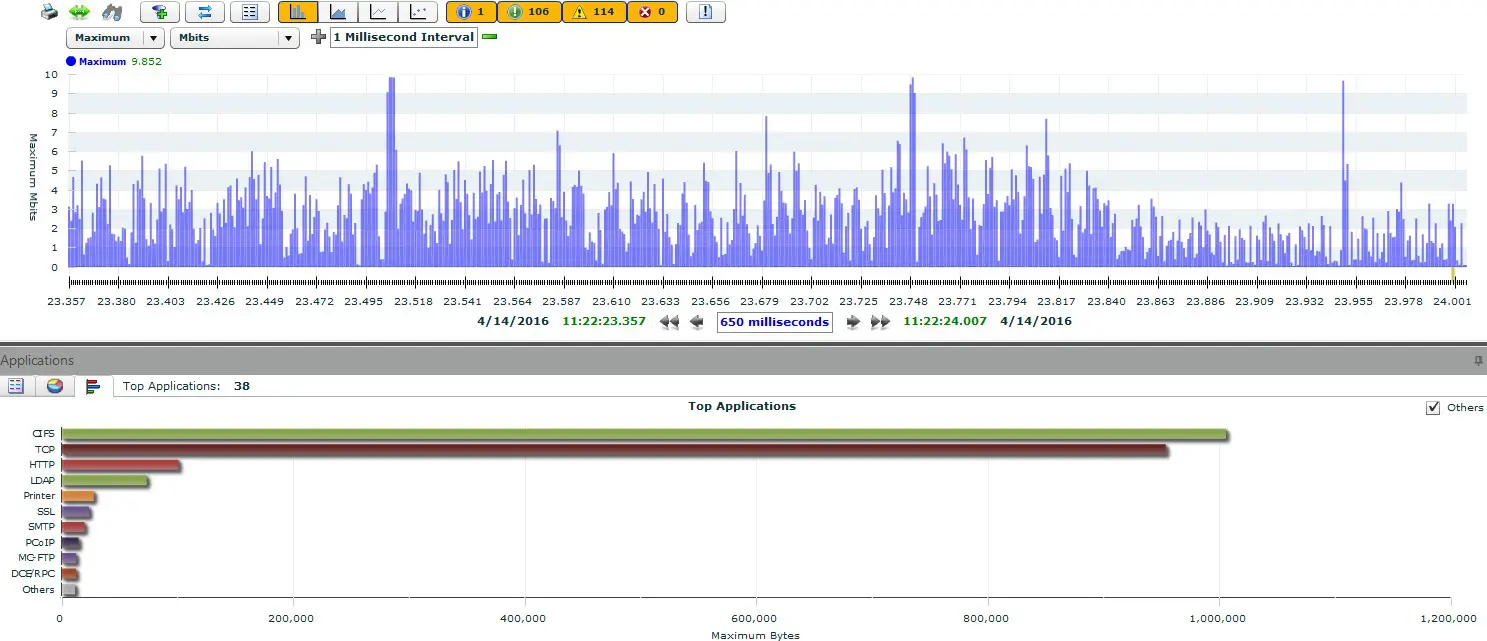
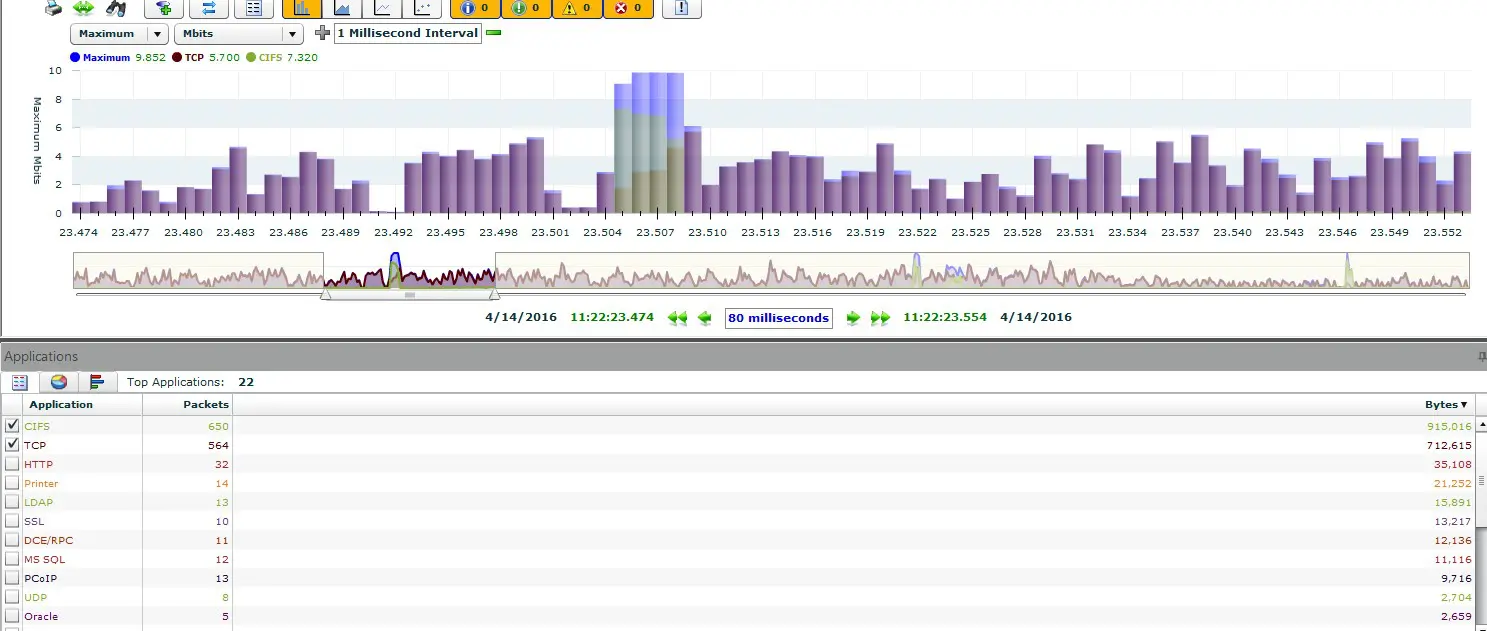
Während des Tests zeigt der VulcanManager bereits einige nützliche Daten an, wie beispielsweise die TCP Connections oder den Layer 1 Durchsatz. Anhand der Grafiken im oberen Bereicht bekommt man auf einen Blick einen guten Eindruck. Im folgenden Screenshot lässt sich so erkennen, dass die Anzahl der aktiven Verbindungen weniger als die Hälfte der geplanten schafft (schlecht), während der Layer 5-7 Goodput einen unschönen Knick zu Beginn des Tests hat. Beide Probleme haben sich im Nachgang als Fehler bei der IPv6 Implementation des getesteten Geräts herausgestellt.
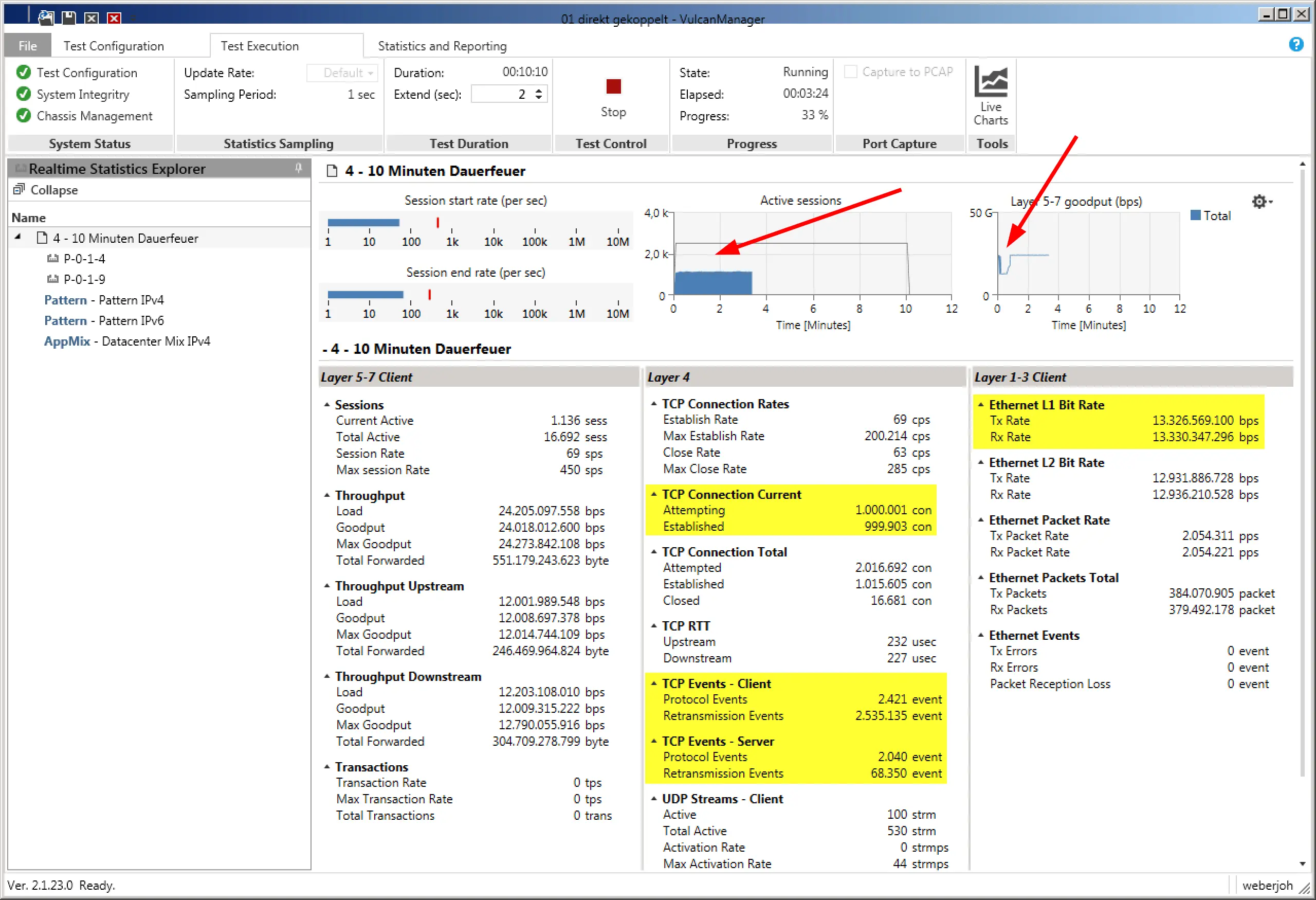
Während theoretisch 2 Millionen Sessions bei 80 G Durchsatz die Firewall hätten passieren sollen, ist hier weniger als die Hälfte sauber durchgekommen.
2) Hohe Anzahl von Verbindungen (Session Load): Ebenfalls für IPv4 und IPv6 wurden bei diesem Test 20 Millionen parallele TCP Sitzungen aufgebaut und aufrechterhalten. Nicht nur die Summe der Sessions war relevant, sondern vor allem die kurze Ramp-Up Zeit von nur 30 Sekunden, was einem Aufbaurate von 667.000 Verbindungen pro Sekunde entsprach! Für 60 Sekunden wurden die Sessions stehen gelassen, jedoch ohne Daten zu transferieren. Über weitere 30 Sekunden wurden sie, TCP-typisch per FIN-ACK, wieder abgebaut. Ziel war es, dass die zu testenden Firewalls erstens die Verbindungen alle sauber durchließen und sie zweitens auch wieder sauber aubbauen (und somit ihren Speicher freigeben) konnten.
3) NAT Szenarien: Hierbei wurde genau der gleiche Test wie unter 1) verwendet, mit dem einzigen Unterschied, dass die IPv4 Verbindungen vom Client- zum Servernetz mit einem Source-NAT auf den Firewalls versehen wurden. Ziel war es herauszufinden, ob dies eine Leistungsverringerung bei den Firewalls verursacht.
4) Realistischer Traffic: Per vordefiniertem „Datacenter Mix“ konnten wir mit wenigen Klicks den Ablauf von zwei HTTPS, SMB2, LDAP und AFS (über UDP und TCP) Verbindungen für mehrere Tausend Nutzer simulieren. Hierbei ging es nicht um einen vollen Lasttest der Firewalls, sondern um die Auf- und Abbaugeschwindigkeiten sowie die Applikationserkennungen. Je nachdem, ob die App-IDs der Firewalls aktiviert oder deaktiviert waren, gab es hier große Unterschiede.
5) 10 Minuten Dauerfeuer mit Commits: Dieser etwas speziellere Tests bestand aus den Szenarien 1 und 4, also volle Last (1) bei gleichzeitig konstantem Session Auf- und Abbau (4). Dies lief für 10 Minuten konstant durch, während wir weitere 500 Regeln auf die jeweilige Firewall installiert haben. Hierbei wollten wir herausfinden, ob dieser Prozess auf den Firewalls einen messbaren Knick in dem Durchsatz erzeugt, was teilweise auch der Fall war.
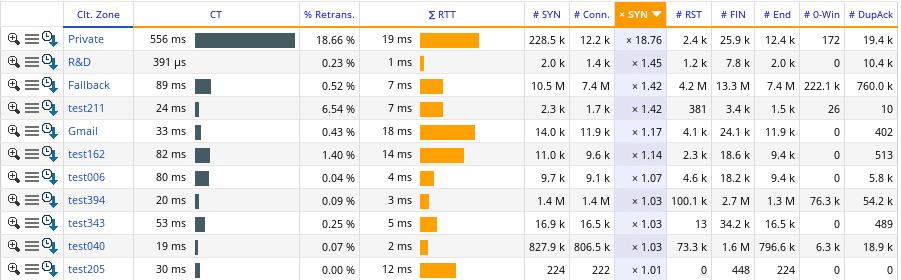
Am Ende eines jeden Tests zeigt der VulcanManager die „Statistics and Reporting“ Seite mit allen erdenklichen Details an. Per „Create Report“ lässt man sich ein PDF erstellen, was neben allen Details auch Informationen über das gewählte Testszenario sowie Angaben zu dem getesteten Gerät beinhält. Die Herausforderung besteht darin, die relevanten von den weniger relevanten Zahlen zu unterscheiden und sie in den richtigen Kontext zu stellen um letztendlich aussagekräftige Ergebnisse zu bekommen. Während unserer Vergleiche von verschiedenen Next-Generation Firewalls beschränkten wir uns beispielsweise rein auf den „Layer 1 steady throughput (bps)“ für den Durchsatz-Test, oder die „Successful TCP Connections“ für den Verbindungs-Test. Verglichen mit den Referenzwerten bei denen der VulcanBay mit sich selbst verbunden war, gab dies bereits sinnvoll vergleichbare Ergebnisse, die sich sowohl tabellarisch als auch grafisch einfach darstellen ließen.
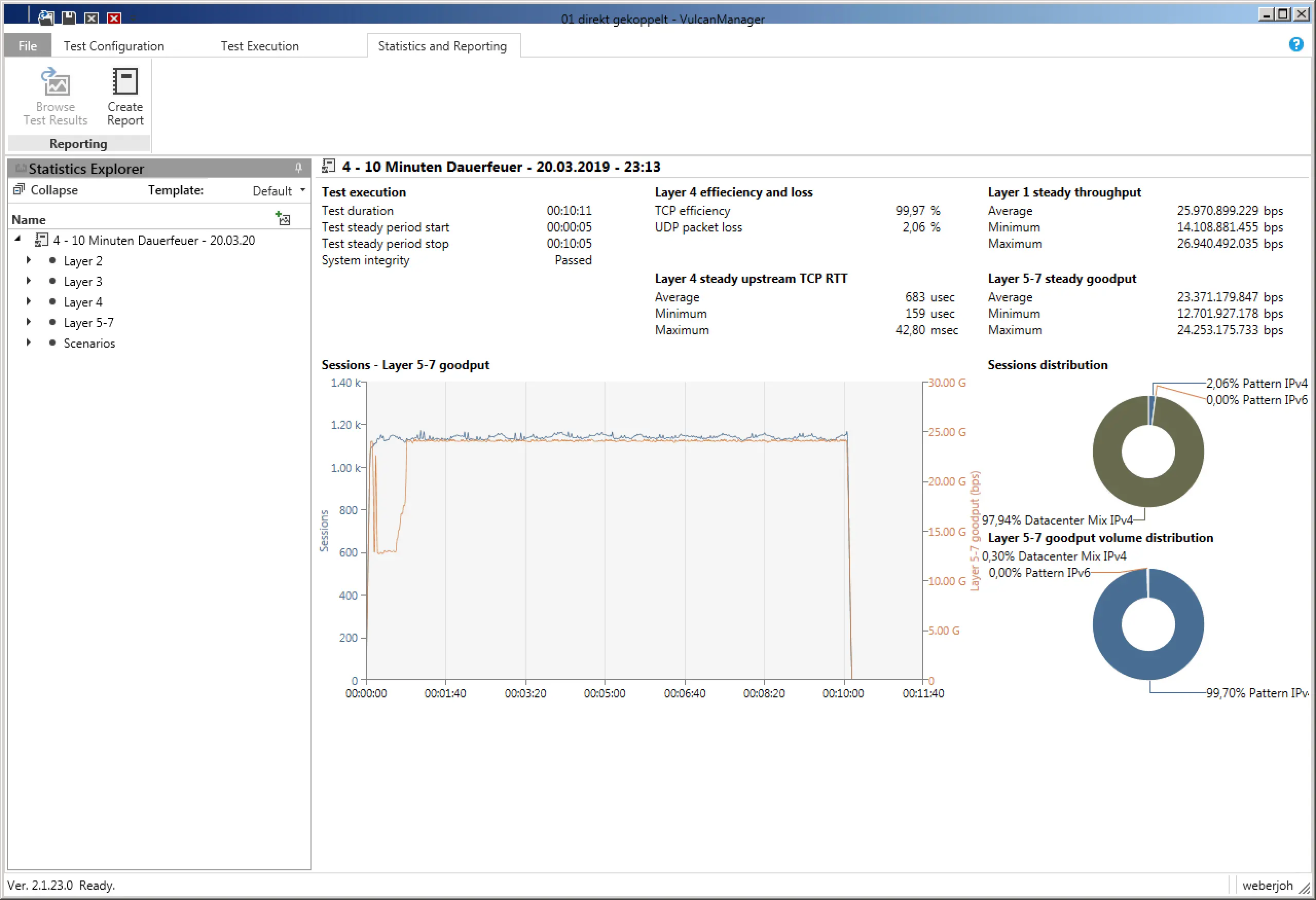
Die Statistics and Reporting Seite gibt neben einem groben Überblick (Mitte) die Möglichkeit, Testwerte aus allen OSI-Schichten und der gewählten Testszenarios auszulesen (Links, aufklappbare Reiter).
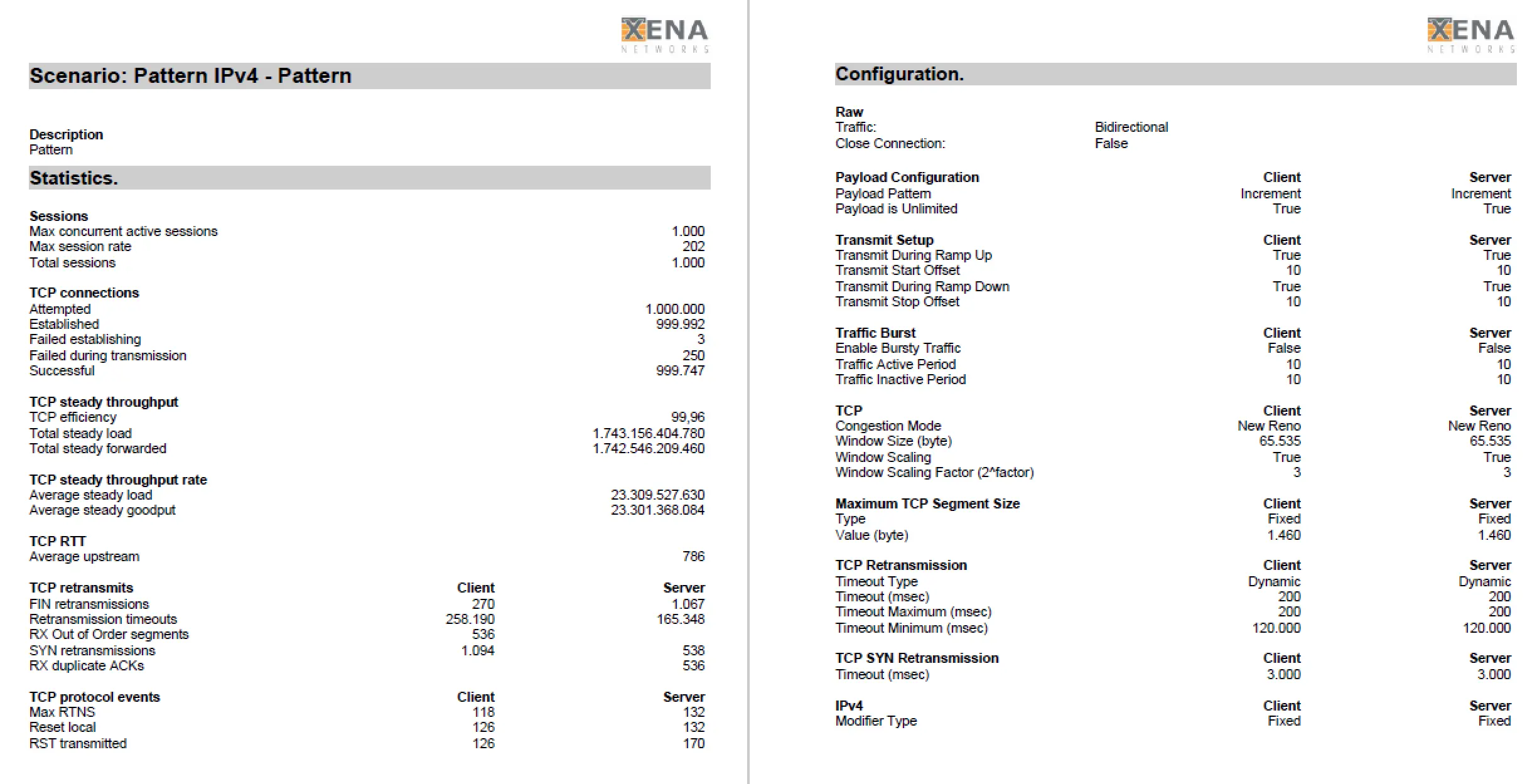
Ausschnitt eines PDF Reports mit allen Details.
Beachten Sie, dass der VulcanManager einige weitere interessante Funktionen hat, die wir in dieser Fallstudie nicht verwendet haben, wie TLS Traffic (zum Testen von TLS-Interception) und Packet Replay (zum Testen eigener und spezifischerer Szenarien, die aus hochgeladenen PCAPs extrahiert werden). Auch haben wir nicht viele anwendungs- oder protokollorientierte Testszenarien wie Dropbox, eBay, LinkedIn oder HTTPS, IMAP, NFS genutzt. Dies ist auf unsere Testzwecke zurückzuführen, die stark auf den reinen Durchsatz und Anzahl der Sessions fokussiert waren.
Der VulcanBay von XENA Networks ist das ideale Testgerät für die Vergleiche diverser Next-Generation Firewalls. Innerhalb kürzester Zeit hatten wir diverse Testszenarien konfiguriert und getestet. Lediglich die Fülle an Testergebnissen war anfänglich überfordernd. Die Kunst bestand darin, sich gezielt auf die relevanten Informationen zu konzentrieren.