Datendioden gewährleisten eine unidirektionale Kommunikation und stellen sicher, dass der Datenverkehr im Netzwerk, gleichgültig was für ein Medientyp zum Einsatz kommt, nur in eine Richtung fliessen kann.
Unidirektionale Netzwerkgeräte mit Datendiodenfunktionalität werden in der Regel eingesetzt, um die Informationssicherheit oder den Schutz kritischer digitaler Systeme (KRITIS), wie z. B. industrieller Kontrollsysteme oder Produktivnetze vor Cyberangriffen zu gewährleisten.
Diese Datendiodenfunktion ist in einem Netzwerk-TAs (Test Access Points) von entscheidender Bedeutung, da sie dazu beiträgt, dass der Netzwerkverkehr nur in die vorgesehene Richtung fließt und dass jeglicher unbefugte Zugriff des Netzwerks verhindert wird und dabei hilft Datenmanipulationen und -abflüsse zu verhindern.
Datendioden-Funktion bei aktiven Netzwerk-TAPs
Indem sie den Datenfluss nur in eine Richtung zulässt, stellt eine Datendiode sicher, dass sensible oder vertrauliche Informationen im Netzwerk nicht von unbefugten Benutzern eingesehen oder gestohlen werden können. Dies ist besonders wichtig für Organisationen, die mit sensiblen Daten umgehen, wie Finanzinstitute und Regierungsbehörden.
Ein weiterer wichtiger Vorteil der Datendiodenfunktion in Netzwerk-TAPs besteht darin, dass sie beispielsweise böswillige Angriffe auf das Netzwerk zu verhindern hilft.
Durch den unidirektionalen Datenfluss kann eine Datendiode Hacker daran hindern, auf das Netzwerk zuzugreifen und Malware oder andere bösartige Software zu installieren. Dies trägt wiederum dazu bei, das Netzwerk vor einer Vielzahl von Bedrohungen zu schützen, darunter Viren, Ransomware und Denial-of-Service-Angriffe.
Zusammenfassend lässt sich sagen, dass die Datendiodenfunktion eine wichtige Komponente in Netzwerk-TAPs ist, da sie maßgeblich dazu beiträgt, die Sicherheit und Integrität des Netzwerkverkehrs zu gewährleisten. Da sie rückwirkungsfrei Datenfluss nur in eine Richtung zulässt, kann sie Datenverletzungen und böswillige Angriffe verhindern und die Verfügbarkeit des Netzwerks verbessern.
Fazit
Unternehmen, die mit sensiblen Daten umgehen, sollten die Integration der Datendiodenfunktion in ihre Netzwerk-TAPs in Betracht ziehen, um ihre Netzwerksicherheit zu gewährleisten.
In meinem aktuellen Beitrag möchte ich auf das Thema Netzwerkzugriff mittels Netzwerk-TAP eingehen und Ihnen die Vorteile dieser Technik aufzeigen.
Netzwerke sind heutzutage das Kernelement für den Transport von Kommunikationsdaten und den Austausch von elektronischen Informationen. Die Zahl der netzwerkfähigen Produkte nimmt rapide zu und das Medium Internet ist längst zu einem festen Bestandteil unseres Lebens geworden.
Auch im Heimbereich setzen Hersteller mehr und mehr auf netzwerkfähige Elemente und ermöglichen dadurch den Anwendern einen ortsunabhängigen und komfortablen Zugriff (auf solche Geräte).
Ein Leben ohne Internet ist kaum noch denkbar und heutige Computer Netzwerke nehmen einen sehr großen Stellenwert ein.
Was aber, wenn das Netzwerk ausfällt oder nicht in gewohnter Weise zur Verfügung steht?
Die Auswirkung eines Netzwerk Ausfalles kann gigantische finanzielle Folgen nach sich ziehen und durchaus ein weltweites Chaos auslösen.
Durch ein proaktives Monitoring System können Sie Ihre IT Dienstgüte kontinuierlich überwachen und somit das Risiko eines Ausfalles deutlich minimieren.
Eine permanente Überwachung Ihrer IT Infrastruktur hilft Ihnen auch bei Investitionsentscheidungen, da Sie über die gewonnenen Informationen detaillierte Analysen und Auswertungen erhalten und somit Tendenzen ableiten können. Gerade wenn es um Kapazitätsplanungen oder die Sicherstellung von QoS (Quality of Service) geht, ist ein umfangreiches Monitoring unumgänglich.
Ein Netzwerk Monitoring System ist kein Produkt von der Stange und in diesem Beitrag geht es um Netzwerk Monitoring durch das sogenannte „Packet Capture" Verfahren. Bei dieser Methode werden alle zu analysierenden Netzwerkdaten Byte für Byte ausgewertet. Dabei werden die übertragenen digitalen Informationen mittels Capturing aufgezeichnet und von dem Monitoring Tool analysiert.
Doch woher kommen diese Daten und wie verlässlich sind diese Informationsquellen?
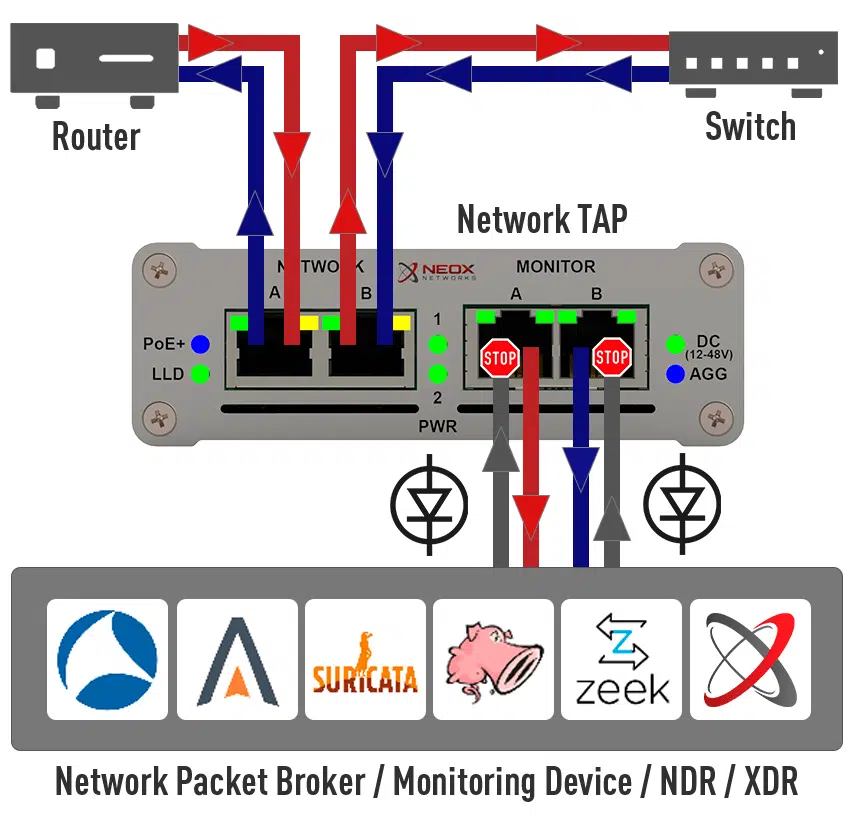
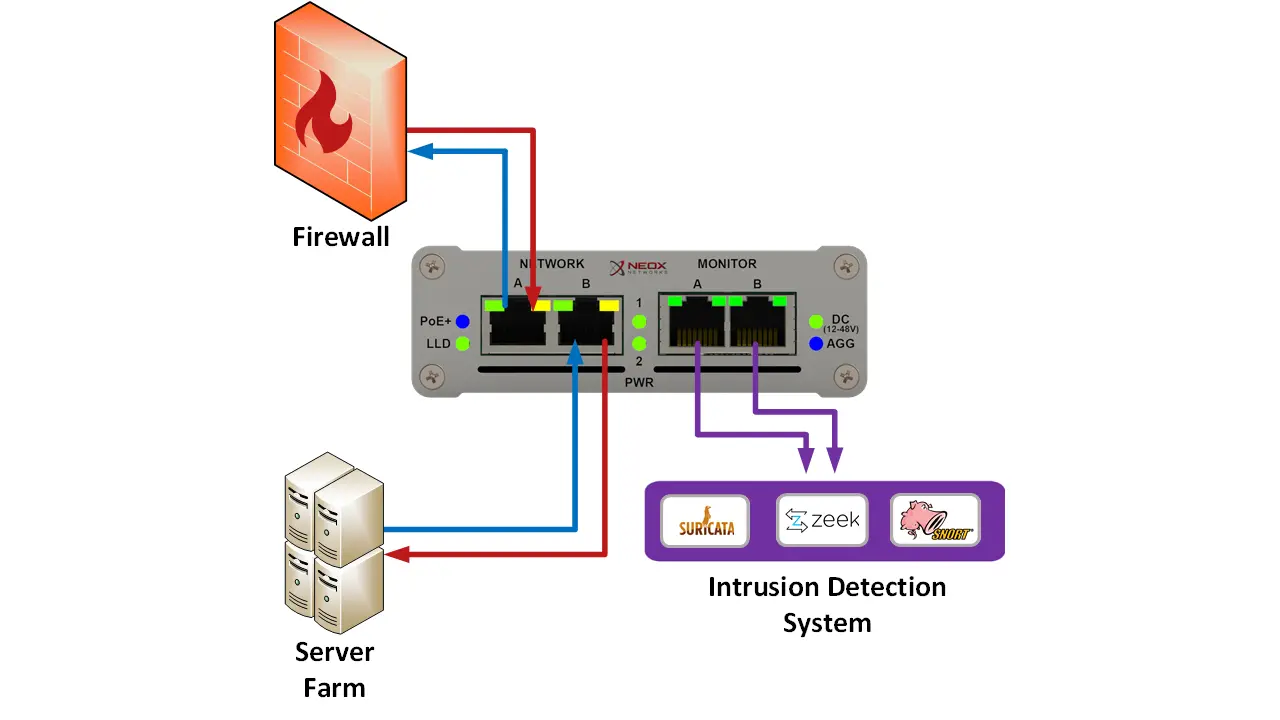
Am besten eignen sich für diese Messtechnik Netzwerk-TAPs. Was sind das für Geräte und wie werden diese eingesetzt?
Netzwerk-TAPs besitzen in der Regel vier physikalische Ports und werden transparent in die zu analysierende Netzwerkleitung eingeschleift. Dabei werden die auf den Netzwerk Ports übertragenen Informationen auf die Monitoring Interfaces gespiegelt.
Durch diese Technik bekommt man einen 100%’igen Einblick in das Netzwerk Geschehen und kann die Daten ohne Auswirkung auf die Netzwerk Performance analysieren. Da jedes einzelne übertragene Netzwerkpaket aus der Leitung herauskopiert wird, wäre man mit dieser Methode auch in der Lage, ein „Backup" seiner Netzwerkdaten anzulegen.
Technische Vorteile von Netzwerk-TAPs:
Netzwerk-TAPs beeinträchtigen die Funktion der aktiven Netzwerkleitung keinesfalls
100% transparent und unsichtbar für Hacker und andere Angreifer
Netzwerk-TAPs sind passiv und verhalten sich wie eine Kabelbrücke (fail-closed) im Fehlerfall
Leiten die Netzwerkdaten vollständig aus
Die Integrität der Daten ist gewährleistet
Netzwerkpakete mit CRC Fehlern werden ebenso ausgeleitet
Nicht konforme Daten nach IEEE 802.3 werden herauskopiert
Arbeitet protokollunabhängig und unterstützt Jumbo Frames
Klassische Netzwerk-TAPs leiten die Daten im Voll-duplex Modus aus
Überbuchung der Ausgangsports ausgeschlossen
Keine lästige Konfiguration nötig, einmal installiert, liefert es die gewünschten Daten
Fehler durch falsche Paketreihenfolge ausgeschlossen
Konfigurationsfehler ausgeschlossen, da Inbetriebnahme durch Plug’n Play erfolgt
Medienkonvertierende Netzwerk-TAPs erhältlich für größtmögliche Einsatzgebiete
Haben Sie Performance Probleme im Netzwerk oder bereits einen Ausfall, ist meist schnelles Handeln angesagt. In solchen Situation hat man wenig Zeit, um SPAN-Ports zu konfigurieren und möchte sofort mit dem Troubleshooting loslegen.
Was aber, wenn zu diesem Zeitpunkt kein SPAN-Port zur Verfügung steht oder das Passwort zum Switch gerade nicht zur Hand ist? Aber es kann auch noch viel schlimmer kommen, nämlich, dass der Switch durch einen DDoS Angriff oder eine bandbreitenintensive Anwendung ausgelastet ist und aufgrund dessen eine Analyse am SPAN-Port quasi unmöglich ist. Auch könnte es passieren, dass der Switch durch einen böswilligen Angriff nicht in gewohnter Weise zur Verfügung steht.
Gerade aus Sicherheitsgründen oder um Wirtschaftsspionage zu ermitteln, sind Netzwerk-TAPs unerlässlich, da Sie auf physikalischer Ebene die Daten, gleichgültig was im Netzwerk passiert, ausleiten und somit stets eine zuverlässige Netzwerkanalyse und Monitoring erlauben.
Es gibt viele Gründe, Netzwerk-TAPs gegenüber dem SPAN-Port zu priorisieren und wir hoffen, dass wir Ihnen in diesem Artikel einen Überblick über die Vorzüge näherbringen konnten.
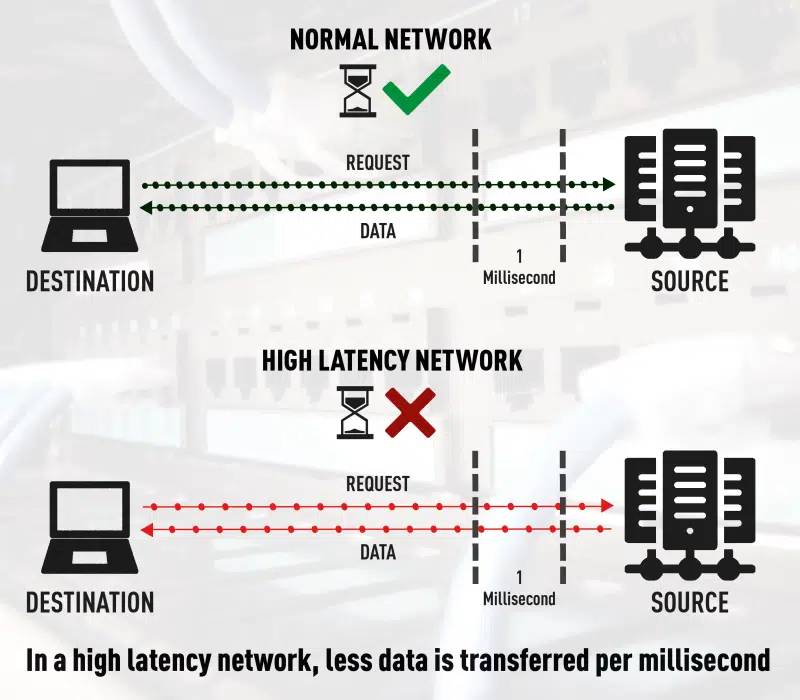
Es ist noch nicht so lange her, dass Unternehmen ihre kritischen Geschäftsanwendungen ausschließlich in eigenen Netzwerken von Servern und Client-PCs untergebracht haben. Die Überwachung und Fehlerbehebung von Leistungsproblemen, wie zum Beispiel der Latenz, war einfach umzusetzen.
Obwohl sich Tools zur Netzwerküberwachung und Diagnose stark verbessert haben, hat die Einführung einer Vielzahl von miteinander verbundenen SaaS-Anwendungen und Cloud-gehosteten Diensten die typische Netzwerkkonfiguration stark verkompliziert, was negative Auswirkungen haben kann.
Da Unternehmen immer mehr Anwendungen und Datenhosting an externe Anbieter outsourcen, führt dies immer schwächere Links in das Netzwerk ein. SaaS-Dienste sind im Allgemeinen zuverlässig, aber ohne eine dedizierte Verbindung können sie nur so gut sein, wie die Internetverbindung, die sie verwenden.
Aus Sicht des Netzwerkmanagements besteht das sekundäre Problem bei extern gehosteten Apps und Services darin, dass das IT-Team weniger Kontrolle und Transparenz hat, was es schwieriger macht, dass Dienstleistungsanbieter im Rahmen ihrer Dienstleistungsvereinbarungen (SLAs) bleiben.
Die Überwachung des Netzwerkverkehrs und die Fehlerbehebung innerhalb der relativ kontrollierten Umgebung einer Unternehmenszentrale, ist für die meisten IT-Teams zu bewältigen.
Unterschied zwischen normaler und hoher Netzwerk-Latenz
Aber für Organisationen, die auf einem verteilten Geschäftsmodell beruhen, mit mehreren Zweigstellen oder Mitarbeitern an entfernten Standorten, führt die Verwendung dedizierter MPLS-Leitungen schnell zu hohen Kosten.
Wenn Sie bedenken, dass der Datenverkehr von Anwendungen wie Salesforce, Skype for Business, Office 365, Citrix und anderen, in der Regel den Hauptgeschäftssitz umgehen, ist es nicht verwunderlich, dass Latenz immer häufiger auftritt und immer schwieriger zu beheben ist.
Einer der ersten Opfer der Latenz ist die VoIP-Anrufqualität, die sich in unnatürlichen Verzögerungen bei Telefongesprächen manifestiert. Mit dem explosionsartigen Wachstum von VoIP und anderen UCaaS-Anwendungen wird dieses Problem jedoch weiter zunehmen.
Ein weiterer Bereich, in dem die Latenz ihren Tribut fordert, sind Datenübertragungsgeschwindigkeiten. Dies kann zu einer Reihe von Problemen führen, insbesondere wenn große Datendateien oder medizinische Aufzeichnungen von einem Ort zu einem anderen übertragen oder kopiert werden.
Auch bei großen Datentransaktionen, wie einer Datenbankreplikation, kann die Latenz ein Problem darstellen, da mehr Zeit für die Durchführung von Routineaktivitäten erforderlich ist.
Auswirkungen von dezentralisierten Netzwerken und SaaS
Bei so vielen Verbindungen zum Internet, von so vielen Standorten aus, macht es Sinn, dass die Leistungsüberwachung von Unternehmensnetzwerken aus dem Datenzentrum heraus erfolgt. Einer der besten Ansätze besteht darin, Tools zu finden, welche die Verbindungen an allen Remote-Standorten überwachen.
Die meisten von uns verwenden fast täglich Anwendungen wie Outlook, Word und Excel. Wenn wir Office 365 verwenden, sind diese Anwendungen wahrscheinlich so konfiguriert, dass sie sich mit Azure verbinden und nicht mit dem Unternehmensdatencenter.
Wenn das IT-Team die Netzwerkleistung nicht direkt in der Zweigstelle überwacht, verliert es die User Experience (UX) an diesem Standort vollständig aus den Augen. Sie denken vielleicht, dass das Netzwerk gut funktioniert, während die Benutzer tatsächlich wegen eines bislang nicht diagnostizierten Problems frustriert sind.
Wenn Datenverkehr von SaaS-Anbietern und anderen cloudbasierten Speicheranbietern von und zu einem Unternehmen weitergeleitet wird, kann dies durch Jitter, Trace-Route und manchmal auch Rechengeschwindigkeit negativ beeinträchtigt werden.
Dies bedeutet, dass Latenz für die Endbenutzer und Kunden zu einer sehr ernsthaften Einschränkung wird. Die Zusammenarbeit mit Anbietern, die sich in der Nähe der benötigten Daten befinden, ist eine Möglichkeit, um potenzielle Probleme aufgrund von Entfernungen zu minimieren. Aber selbst in einem parallelen Prozess haben Sie möglicherweise Tausende oder Millionen von Verbindungen, die versuchen auf einmal durchzukommen. Dies führt zwar zu einer eher geringen Verzögerung, jedoch bauen sie sich auf und werden über weite Distanzen immer größer.
Gründe für Netzwerk-Latenzen
Ist maschinelles Lernen die Antwort auf eine hohe Netzwerklatenz?
Früher war es so, dass jedes IT-Team klare Netzwerkpfade zwischen seinem Unternehmen und Rechenzentrum definieren und überwachen konnte. Sie konnten Anwendungen steuern und regulieren, die auf internen Systemen ausgeführt wurden, da alle Daten lokal installiert und gehostet wurden, ohne auf die Cloud zuzugreifen.
Dieses Kontrollniveau ermöglichte einen besseren Einblick in Probleme wie Latenz und ermöglichte es ihnen eventuell auftretende Probleme schnell zu diagnostizieren und zu beheben.
Fast zehn Jahre später hat die Verbreitung von SaaS-Anwendungen und Clouddiensten nun die Leistungsdiagnostik von Netzwerken so kompliziert gemacht, dass neue Maßnahmen erforderlich sind.
Was ist die Ursache für diesen Trend? Die einfache Antwort ist eine zusätzliche Komplexität, Distanz und mangelnde Sichtbarkeit. Wenn ein Unternehmen seine Daten oder Anwendungen an einen externen Anbieter überträgt, anstatt sie lokal zu hosten, fügt dies effektiv eine dritte Partei in den Mix der Netzwerkvariablen ein.
Jeder dieser Punkte führt zu einer potenziellen Schwachstelle, die sich auf die Netzwerkleistung auswirken kann. Diese Dienste sind zwar größtenteils recht stabil und zuverlässig, aber Ausfälle bei einem oder mehrerer Dienste kommen selbst bei den Branchengrößten vor und können sich auf Millionen von Benutzern auswirken.
Tatsache ist, dass es viele Variablen in einer Netzwerklandschaft gibt, die von den IT-Teams der Unternehmen nicht mehr kontrolliert werden können.
/p>Eine Möglichkeit, mit der Unternehmen versuchen die Leistung sicherzustellen, besteht darin, einen dedizierten MPLS-Tunnel zu nutzen, welcher zur eigenen Unternehmenszentrale oder ins Datenzentrum führt. Aber dieser Ansatz ist teuer und die meisten Unternehmen nutzen diese Methode nicht für ihre Zweigstellen. Dies hat zur Folge, dass Daten aus Anwendungen wie Salesforce, Slack, Office 365 und Citrix nicht mehr durch das Rechenzentrum des Unternehmens übertragen werden, da sie dort nicht mehr gehostet werden.
Bis zu einem gewissen Grad kann die Latenz durch die Verwendung traditioneller Methoden zur Überwachung der Netzwerkleistung gemindert werden, aber eine Latenz ist naturgemäß nicht vorhersehbar und schwer zu verwalten.
Wie sieht es jedoch mit künstlicher Intelligenz aus? Wir alle haben Beispiele von Technologien gehört, die große Fortschritte machen, indem sie eine Form des maschinellen Lernens verwenden. Leider sind wir jedoch nicht an dem Punkt, an dem maschinelle Lernverfahren die Latenz signifikant minimieren können.
Wir können nicht genau vorhersagen, wann ein bestimmter Switch oder Router mit Datenverkehr überlastet wird. Das Gerät kann einen plötzlichen Datenburst erleben, der nur eine Verzögerung von einer Millisekunde oder sogar zehn Millisekunden verursacht. Tatsache ist, sobald diese Geräte überlastet sind, kann das maschinelle Lernen bei diesen plötzlichen Änderungen noch nicht helfen, Warteschleifen von Paketen, die auf eine Verarbeitung warten, zu verhindern.
Die zur Zeit effektivste Lösung besteht darin, die Latenz dort zu bekämpfen, wo sie die Benutzer am meisten beeinflusst – so nah wie möglich an ihrem physischen Standort.
In der Vergangenheit nutzten die Techniker Netflow und/oder eine Vielzahl von Überwachungsinstrumenten im Rechenzentrum, da sie genau wussten, dass der Großteil des Datenverkehrs zu ihrem Server gelangte und dann zu ihren Kunden zurückkehrte. Bei einer so viel größeren Datenverteilung gelangt heute nur ein kleiner Teil der Daten zu den Servern, was eine Überwachung des eigenen Datenzentrums weit weniger effizient macht.
Anstatt sich ausschließlich auf ein solches zentralisiertes Netzwerküberwachungsmodell zu verlassen, sollten IT-Teams ihre herkömmlichen Tools ergänzen, indem sie die Datenverbindungen an jedem Remote-Standort oder in jeder Zweigstelle überwachen. Im Vergleich zu heutigen Praktiken ist dies eine veränderte Denkweise, aber sie macht Sinn: Wenn die Daten verteilt werden, muss auch die Netzwerküberwachung verteilt werden.
Anwendungen wie Office 365 und Citrix sind gute Beispiele, da die meisten von uns regelmäßig Produktivitäts- und Unified Communications Tools verwenden. Diese Anwendungen werden wahrscheinlich eher mit Azure, AWS, Google oder anderen verbunden, als mit dem eigenen Unternehmensdatencenter. Wenn das IT-Team diese Zweigstelle nicht aktiv überwacht, verliert es die User Experience an diesem Standort vollständig aus den Augen.
Wählen Sie einen umfassenden und geeigneten Ansatz
Trotz aller Vorteile von SaaS-Lösungen wird die Latenz auch weiterhin eine Herausforderung bleiben, falls IT-Teams von Unternehmen ihre Herangehensweise an das Netzwerkmanagement nicht überdenken.
Kurz gesagt, sie müssen einen umfassenden, dezentralisierten Ansatz für die Netzwerküberwachung verfolgen, der das gesamte Netzwerk und all seine Zweigstellen umfasst. Es müssen ebenfalls bessere Möglichkeiten gefunden werden, die User Experience zu überwachen und bei Bedarf zu verbessern.
Fokussieren Sie sich auf die User Experience
Es besteht kein Zweifel, dass die Verbreitung von SaaS-Tools und Cloud-Ressourcen für die meisten Unternehmen ein Segen war. Die Herausforderung für die IT-Teams besteht jetzt jedoch darin, den Ansatz des Netzwerkmanagements in einem dezentralisierten Netzwerk zu überdenken. Ein wichtiges Thema ist sicherlich die Fähigkeit, effektiv zu überwachen, dass SLAs (Dienstleistungsvereinbarungen) eingehalten werden. Noch wichtiger ist jedoch die Möglichkeit, die Servicequalität für alle Endbenutzer sicherzustellen.
Um das zu erreichen, müssen IT-Experten genau sehen, was die Nutzer in Echtzeit erleben.
Dieser Übergang zu einem proaktiveren Überwachungs- und Fehlerbehebungsstil hilft IT-Fachleuten bei der Behebung von Netzwerk- oder Anwendungsengpässen jeglicher Art, bevor sie für Mitarbeiter oder Kunden problematisch werden.
Fazit
Ergo, um möglichst niedrige Latenzen und eine damit einhergehende optimale User Experience sicherzustellen reicht ein auf zentralen Messpunkten basierendes Monitoring heutzutage meist nicht mehr aus.
Während das Monitoring nach wie vor zentralisiert bleiben kann müssen die Messpunkte zunehmend dezentralisiert werden.
Wie verteile ich meinen Netzwerkverkehr zwecks Analyse möglichst effektiv mittels Load Balancing?
Problemstellung
Oftmals besitzen Analyse-, Monitoring- und Security-Systeme mehr als nur einen Anschluss, um ankommende Daten von den entsprechenden Netzwerk-Abgriffspunkten anzunehmen und zu verarbeiten. Viele dieser Systeme haben mindestens 2, oder aber 4 oder sogar noch mehr Ports, welche zur Datenaufnahme bereitstehen.
Je nach Art und Standort der verschiedenen Netzwerk-Abgriffspunkte bietet das dem Anwender die Möglichkeit pro abgegriffener Leitung einen dedizierten physischen Port zur Verfügung zu stellen. Voraussetzung dafür sind aber mehrere Faktoren.
Die Geschwindigkeit und Topologie der zu analysierenden Netzwerkleitungen muss identisch sein zu den Anschlüssen des Analysesystems und es ist auszuschließen, dass in Zukunft weitere Abgriffspunkte hinzukommen, welche vom gleichen Analysesystem auszuwerten sind.
Lösungsansätze
Abseits der Problematik mit Geschwindigkeiten und Topologien kann man natürlich jederzeit zusätzliche Analysesysteme installieren, sollte die Anzahl der überwachenden Leitungen steigen.
Oftmals ist dies jedoch die kostspieligste und aufwendigste Alternative. Neben der erforderlichen Beschaffung würde es für den Anwender bedeuten, sich mit einem weiteren System auseinander zu setzen; ein vermeidbarer administrativer Mehraufwand.
Um solch eine Situation zu vermeiden, gibt es verschiedene Optionen und je nach bereits vorhandenem Setup kann man technische Verfahren einsetzen, um die ankommenden Daten der Messpunkte effektiver auf die bereits bestehenden physikalischen Ports zu verteilen.
Des Öfteren ist es nämlich primär das Verhältnis von Datenmenge und Anzahl der Messpunkte zu der Anzahl an verfügbaren Ports auf dem Analysesystem und nicht etwa die grundsätzliche Höhe des Datenvolumens, was zu Engpässen physikalischer Natur führen kann.
Hier kann sowohl (semi-dynamisches) Load Balancing als auch Dynamic Load Balancing helfen, ein Feature, welches die meisten Network Packet Broker mitbringen.
Hierbei wird auf dem Network Packet Broker eine Gruppe/Anzahl an physikalischen Ports zusammengefasst und als eine einzelne logische Ausgangsinstanz definiert. Datenströme, welche über diese Portgruppierung den Network Packet Broker verlassen, werden auf alle Ports, welche Teil dieser Gruppierung sind, verteilt, wobei die einzelnen Sessions jedoch erhalten bleiben.
Beispiel
Nehmen wir folgendes Beispiel an: Es wurden 8 Messpunkte im lokalen Netzwerk verteilt gesetzt. Über jeden Abgriffspunkt läuft jeweils eine Session zwischen 2 Endpunkten. Das eingesetzte Analysesystem ist mit insgesamt 4 Ports zur Datenaufnahme ausgestattet.
Selbst wenn man davon ausgeht, dass die Messpunkte ausschließlich SPAN- oder Mirror-Ports sind, besteht immer noch das Problem, dass zu viele Messpunkte auf zu wenige Ports treffen.
Und genau hier kommen die Network Packet Broker mit Load Balancing ins Spiel. Die Lastverteilung sorgt dafür, dass jede Session zwischen 2 Endpunkten eines jeden Messpunktes als Ganzes an einen einzigen Port des angeschlossenen Analysesystems gesendet wird.
Der Einfachheit halber ist anzunehmen, dass die 8 Sessions der 8 Messpunkte zu gleichen Teilen auf die 4 Ports des Analysesystems verteilt werden, pro Port 2 Sessions.
Das alles ist komplett dynamisch und nachträglich hinzukommende Sessions zwischen Endpunkten werden vollautomatisch an die in der Portgruppierung zugehörigen Anschlüsse des Analysesystems gesendet. Eine nachträgliche Einrichtung oder Änderung der Konfiguration des Network Packet Brokers ist nicht nötig, die eingebauten Automatismen erlauben das automatisierte und zuverlässige Verteilen von weiteren Datenströmen an das Analysesystem.
Selbstverständlich ist es auch möglich, sowohl zusätzliche Abgriffspunkte an den Network Packet Broker anzuschließen und deren Daten in die Lastverteilung mit einfließen zu lassen, als auch die oben erwähnte Portgruppierung um zusätzliche Ausgangsports zu erweitern.
All diese Schritte können im laufenden Betrieb vorgenommen werden, die zusätzlichen Datenströme werden in Echtzeit ohne Unterbrechungen an die neu hinzugekommenen Ports des Analysesystems verteilt.
Auch ein Entfernen von Ports, selbst während des Betriebs, ist kein Problem! Der Network Packet Broker ist in der Lage, dafür zu sorgen, dass die Pakete/Sessions ohne Zeit- und Paketverlust an die verbliebenen Ports des Analysesystems weitergereicht werden.
Sessions & Tupels
Doch wie kann der Network Packet Broker sicherstellen, dass immer ganze Sessions auf den einzelnen Ports der oben genannten Load Balancing Gruppe verteilt werden?
Hierfür wird aus jedem einzelnen Paket ein Hash-Wert generiert. Eine integrierte Funktion stellt sicher, dass im Falle einer bi-direktionalen Kommunikation die Pakete beider Transportrichtungen auf demselben Port den Network Packet Broker wieder verlassen.
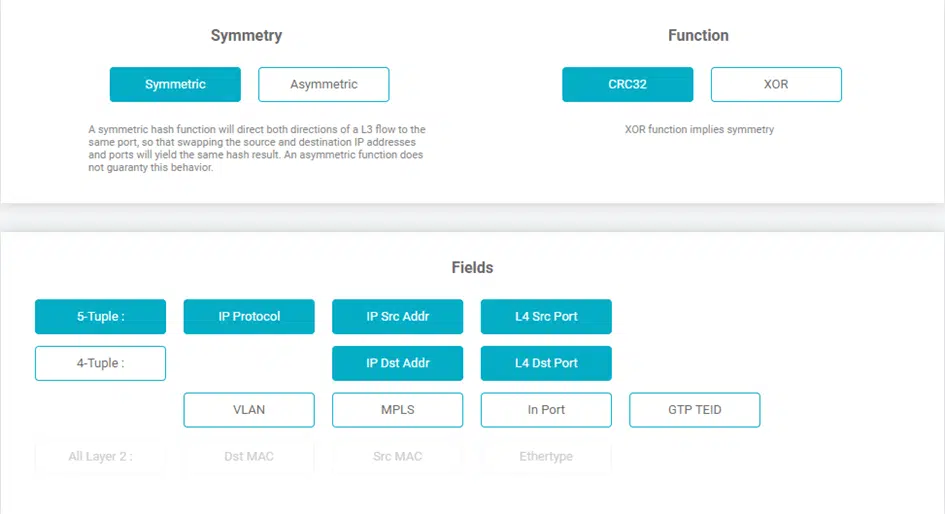
Diese Hash-Werte werden mittels dem sogenannten „5-Tuple“-Mechanismus ermittelt, wobei jedes Tupel ein bestimmtes Feld im Header eines jeden Ethernet-Frames darstellt. Die verfügbaren Tupels auf dem Network Packet Broker (bspw. NEOXPacketLion), welche für die dynamische Lastverteilung genutzt werden, sind:
Input Port (Physikalischer Anschluss)
Ethertype
Source MAC
Destination MAC
VLAN Label
MPLS Label
GTP Tunnel Endpoint Identifier
GTP Inner IP
IP Protocol
Source IP
Destination IP
Layer-4 Source PORT
Layer-4 Destination PORT
Je nach Struktur und Aufbau des Netzwerks und je nachdem, ob Pakete mittels NAT transportiert werden, ist eine weitere, sehr verbreitete Verteilung der Tupels:
IP Protocol
Source IP
Destination IP
Layer-4 Source PORT
Layer-4 Destination PORT
Bei der „5-Tuple“-basierten Lastverteilung werden alle oben genannten Tupel genutzt, um einen Hash-Wert zu bilden, welcher sicherstellt, dass alle Pakete inklusive der entsprechenden Rückrichtung immer über denselben Port den Network Packet Broker verlassen und somit beispielsweise das eingesetzte Security-System immer und grundsätzlich nur vollständige Sessions zur Auswertung erhält.
Hash-Werte
Um den eigentlichen Hash-Wert überhaupt generieren zu können, auf welchem die Lastverteilung basiert, stehen dem Benutzer zwei verschiedene Funktionen zur Verfügung, CRC32 und XOR.
Mittels der CRC32-Funktion lassen sich Hash-Schlüssel mit einer Länge von 32 Bits generieren und können sowohl symmetrisch als auch asymmetrisch genutzt werden, während die XOR-Funktion einen 16 Bit langen Hash-Schlüssel erstellt, welcher je nach Einsatzzweck eine höher auflösende Verteilung der Daten erlaubt, diese jedoch ausschließlich symmetrisch ausgeben kann.
Diese Symmetrie bedeutet, dass selbst wenn Source IP und Destination IP vertauscht werden, wie man es aus regulären Layer-3-Konversationen kennt, die Funktion dennoch den gleichen Hash-Schlüssel errechnet und damit auch die vollen Layer-3-Konversationen immer auf demselben physikalischen Port den Network Packet Broker verlassen.
Im Falle einer asymmetrischen Verteilung, welche nur von der CRC32-Funktion unterstützt wird, würde der Network Packet Broker PacketLion bei der oben beschriebenen Situation unterschiedliche Hash-Werte errechnen und somit auch entsprechend auf unterschiedlichen physikalischen Ports ausgegeben werden.
NEOXPacketLion Network Packet Broker – Screenshot
Dynamic Load Balancing
Eine weitere, zusätzliche Funktion der Lastverteilung ist die mögliche Dynamik, mit welcher dieses Feature erweitert werden kann. Im Falle einer dynamischen Lastverteilung wird zusätzlich zum oben erklärten Hash-Wert noch die prozentuale Auslastung eines jeden Ports, welcher Teil der Load-Balancing-Portgruppe ist, mit in die Kalkulation einbezogen.
Selbstverständlich werden auch bei diesem Verfahren keine Flows aufgesplittet, weiterhin wird auch sichergestellt, dass, wenn ein Flow basierend auf den Berechnungen auf einem bestimmten Port ausgegeben wird, dieser Flow auch in Zukunft immer über denselben Port den Network Packet Broker verlässt.
Mittels eines konfigurierbaren Timeouts kann der Nutzer definieren, ab wann ein Flow seine Zugehörigkeit zu einem Ausgangsport verliert. Dieser wird bei einem Wiederauftreten dann wieder regulär an die Teilnehmer der Load-Balancing-Portgruppe ausgegeben und sowohl durch Erkennung der Auslastung im TX Stream, als auch anhand der Hash-Wert-Generierung wird ermittelt, welcher Ausganssport des Network Packet Brokers derzeit am geeignetsten ist, um die Daten auf das angeschlossene Analysesystem zu bringen.
Fazit
Es zeigt sich, dass die Verteilung der ankommenden Datenlast mittels Load Balancing seit vielen Jahren ein probates Mittel zur effektiven Ausnutzung von Security-, Analyse- und Monitoring-Systemen ist. Über die Jahre wurde dieses Verfahren immer weiter verbessert und gipfelt in der dynamischen Lastverteilung, welches die PacketLion Serie innehat.
Ein ständiges Nachfassen der Konfiguration in Bezug auf die Verteilung der einzelnen Sessions auf die angeschlossenen Systeme entfällt komplett, dies übernimmt mittlerweile die Intelligenz der Network Packet Broker und erlaubt es dem Anwender, das volle Potential seiner Systeme zu nutzen und unnötige Ausgaben zu vermeiden.
Wie Sie mittels Packet Slicing Monitoring-Ressourcen einsparen und rechtliche Anforderungen einhalten
Problemstellung
Oftmals ist die Schere zwischen einerseits der Kapazität des aufzeichnenden Analysesystems und der Menge an ankommenden Daten so groß, dass ohne entsprechende zusätzliche Mechanismen das Analysesystem höchst-wahrscheinlich nicht in der Lage ist, alle einzelnen Pakete verlustfrei aufzuzeichnen.
Dies ist je nach Einsatzweck eben jenes Analysesystems ein großes Problem, da speziell im Cyber-Security-Umfeld jedes Paket zählt und man andernfalls nicht sicherstellen kann, sämtliche Angriffe und deren Auswirkungen zu erkennen.
Durch nicht rechtzeitig erkannte oder sogar komplett unsichtbar gebliebene Angriffe können den Unternehmen so Schäden in gewaltiger Höhe entstehen, sogar bis hin zu Regressansprüchen von etwaigen Versicherern, wenn diese feststellen sollten, dass deren Klienten nicht ihrer Sorgfaltspflicht nachkamen.
Doch wie entsteht solch eine Situation? Ganz schnell kann es passieren, dass Netze in den Unternehmen wachsen, oftmals parallel mit der geschäftlichen Entwicklung dieses Unternehmens, während die oftmals bereits vorhandenen Analyse- und Monitoringsysteme, bei der Beschaffung mit Reserven eingeplant, immer öfter und häufiger an das Ende ihrer Reserven stoßen.
Höhere Bandbreiten, immer mehr Dienste und Schnittstellen, welche im LAN eingesetzt werden, reduzieren die Kapazitäten, bis zu dem Punkt, an welchem die Systeme nicht mehr mithalten können und Pakete verwerfen müssen.
Ab diesem Moment ist es theoretisch möglich, dass ein Angreifer sich unentdeckt im lokalen Netz aufhält, da das Analysesystem hoffnungslos überlastet ist. Der Administrator ist nicht mehr in der Lage, zu erkennen, welche Parteien in seinem Netz miteinander sprechen, welche Protokolle sie nutzen und mit welchen Endpunkten außerhalb des LANs kommuniziert wird.
Oftmals sind jedoch nicht Kapazitätsprobleme der Auslöser für das Aktivieren von Packet Slicing, sondern vielmehr datenschutzrechtliche Gründe. Je nachdem, wo und welche Daten wann abgegriffen werden, kann es für das Unternehmen verpflichtend sein, dass nur solche Daten aufgezeichnet und ausgewertet werden, welche keinerlei personenbezogene bzw. leistungsbezogene Informationen beinhalten.
Während typischerweise der Paketkopf nur Verbindungsdaten enthält (WANN, WER, WIE, WO), finden sich in den Nutzdaten, obwohl meist verschlüsselt, eben jene inhaltlichen Daten, welche es theoretisch ermöglichen, die Leistung der einzelnen Anwender zu bemessen. Je nach Einsatzort ist dies jedoch oft weder gewollt oder erlaubt. Es muss daher sichergestellt werden, dass es dem Administrator nicht möglich ist, persönliche Informationen aus den aufgezeichneten Daten zu rekonstruieren.
Analysedaten reduzieren mittels Packet Slicing
Und genau an diesem Punkt kommt das Feature „Packet Slicing“ ins Spiel: mit diesem Verfahren ist es möglich, die ankommende Datenlast an Ihrem Analysesystem um bis zu 87% zu reduzieren (bei 1518 Bytes Paketgröße undPacket Slicing bei 192 Bytes), indem von jedem Paket die Nutzdaten einfach entfernt werden.
Viele Analyse- und Monitoring-Ansätze benötigen für ihre Auswertungen und Analysen nur die Informationen, welche im Paketheader gespeichert sind, sprich die Metadaten, während die Nutzdaten oftmals keine wichtigen oder verwertbaren Informationen enthalten, da diese sowieso meistens verschlüsselt sind und somit nicht für die Auswertung verwendet werden können. Durch eben jenes Entfernen der Nutzdaten ist eine massive Entlastung der verarbeitenden Instanz zu erwarten und dieses ermöglicht teilweise sogar noch eine größere Abdeckung des LANs durch das Monitoring- und Analysegerät.
FCS-Prüfsummenproblematik
Ein wichtiger Aspekt beim Packet Slicing ist die Wiederherstellung der FCS-Prüfsumme eines jeden geänderten Pakets. Da durch das Wegschneiden der Nutzdaten in die Struktur und Länge des Paketes eingegriffen wird, ist die ursprünglich berechnete Prüfsumme, welche vom Absender errechnet und in das FCS-Feld des Paketkopfes eingetragen wurde, nicht mehr korrekt.
Sobald ein solches Paket auf dem Analysesystem ankommt, werden jene Pakete verworfen oder als fehlerhaft deklariert, da die Prüfsumme im FCS-Feld immer noch auf der ursprünglichen Paketlänge basiert. Um dem entgegen zu wirken, ist es essentiell, dass die FCS-Prüfsumme für jedes Paket, von welchem die Nutzdaten entfernt wurden, neu berechnet und auch eingetragen wird, da dies sonst die Analysesysteme zwingen würde, diese Pakete als fehlerhaft und/oder manipuliert einzustufen.
Network Packet Broker als Packet Slicer
Generell gibt es mehrere Möglichkeiten, an welchen Stellen in der vom Kunden eingesetzten Visibility-Plattform das oben genannte Packet Slicing aktiviert werden kann. Dies ist einerseits eine Entscheidung von Fall zu Fall, andererseits auch eine technische.
Davon ausgehend, dass der Anwender mehrere Messpunkte in seinem Netzwerk verteilt gesetzt hat, wird oftmals ein Network Packet Broker eingesetzt. Dieses Gerät ist eine weitere Aggregationsebene und wird typischerweise als letzte Instanz direkt vor dem Monitoring-System eingesetzt. Ein Network Packet Broker ist optisch sehr nah an einem Switch und ermöglicht es dem Anwender, die Daten von multiplen Messpunkten (Netzwerk-TAPs oder SPAN-Ports) zentral zusammen- zuführen und aggregiert in einem oder mehreren Datenströmen an das zentrale Analysesystem zu senden.
Somit können z.B. die Daten von 10 verteilten Messpunkten, welche in 1Gigabit-Leitungen gesetzt wurden, an ein Analysesystem mit einem einzelnen 10Gigabit-Port gesendet werden, indem der Network Packet Broker diese 1Gigabit-Signale aggregiert und als ein einziges 10Gigabit-Signal wieder ausgibt.
An diesem Punkt erfährt der Anwender jedoch von einem Haken an der ganzen Thematik: Oftmals sind die Analysesysteme, obwohl sie mit einem 10Gigabit-Anschluss ausgestattet sind, nicht in der Lage, auch Bandbreiten von 10Gigabit/Sekunde zu verarbeiten.
Dies kann verschiedenste Gründe haben, welche jedoch nicht Thema dieses Blogeintrags sein sollen. Allerdings ist die Ausgangslage prädestiniert für den Einsatz von Packet Slicing; während man im Regelfall seine Monitoring-Infrastruktur mit immensen Kosten erweitern müsste, kann man mit dem Einschalten von Packet Slicing die ankommende Datenflut massiv verringern und somit weiterhin seine bestehenden Systeme nutzen, einzig und allein eine entsprechende Instanz mit eben jenem Feature wird benötigt, welche im Einkauf in aller Regel nur einen Bruchteil dessen kostet, was für ein Upgrade der Analysesysteme zu veranschlagen wäre.
Analysesysteme als Packet Slicer
Eine weitere Möglichkeit bietet sich dem Anwender auf den Analysesystemen selbst. Je nach Hersteller, Aufbau und eingesetzten Komponenten ist es möglich, auf den Systemen selbst direkt die Nutzdaten zu entfernen und die Prüfsumme neu zu berechnen, bevor die Pakete an die entsprechenden Analysemodule intern weitergereicht werden.
In den allermeisten Fällen wird hierfür eine FPGA-basierte Netzwerkkarte benötigt, da sichergestellt werden muss, dass keine CPU-basierte Ressource für die Änderung eines jeden einzelnen Pakets verwendet wird. Nur mittels reiner Hardware-Kapazitäten kann der Anwender sicher sein, dass auch wirklich jedes Paket entsprechend bearbeitet wird, eine andere Herangehensweise könnte wieder zu den eingangs angesprochenen Fehlern und Problemen führen.
Packet Slicing zur Erfüllung rechtlicher Anforderungen
Ein weiterer nennenswerter Aspekt ist die Erfüllung von rechtlichen Anforderungen. Insbesondere im Zusammenhang mit der DSGVO kann es erforderlich sein, die Nutzdaten zu entfernen, da oftmals für eine Analyse die Metadaten zur Auswertung ausreichen.
Beispielsweise, wenn man VoIP analysieren möchte, dann kann mittels Packet Slicing sichergestellt werden, dass nicht autorisierte Personen das Gespräch nicht abhören können, aber man technisch dennoch die Sprachübertragung auswerten und auf Quality-of-Service-Merkmale hin begutachten kann. Somit kann man Performance-Werte auswerten, die Privatsphäre schützen und die gesetzlichen Anforderungen wie eben die DSGVO erfüllen.
Fazit
Wir sehen also, dass es in der Tat verschiedene Möglichkeiten gibt, wie man die finale Last auf den Analyse- und Monitoring-Systemen verteilen oder sogar, wie in diesem Beispiel, verkleinern kann, ohne dass die wichtigsten Informationen zur Erstellung von Performance Charts, Top Talkers und mehr verloren gehen. Packet Slicing stellt somit eine valide Lösung für den Anwender dar, welche sich in fast allen Fällen problemlos realisieren lässt und verwertbare Ergebnisse erzielt.


















 Ein weiterer nennenswerter Aspekt ist die Erfüllung von rechtlichen Anforderungen. Insbesondere im Zusammenhang mit der
Ein weiterer nennenswerter Aspekt ist die Erfüllung von rechtlichen Anforderungen. Insbesondere im Zusammenhang mit der